

Como você garante que suas soluções de IA funcionem conforme o esperado?
Uma breve introdução às avaliações de IA
A IA generativa (GenAI) está evoluindo rapidamente e não se trata mais apenas de chatbots divertidos ou geração de imagens impressionantes. 2025 é o ano em que o foco estará em transformar o entusiasmo em torno da IA em valor real. Empresas em todos os lugares estão buscando maneiras de integrar e aproveitar o GenAI em seus produtos e operações para atender melhor os usuários, aumentar a eficiência, manter a competitividade e impulsionar o crescimento. Com APIs e modelos pré-treinados de provedores líderes, integrar o GenAI parece mais fácil do que nunca. Mas aqui está o cerne da questão: Só porque a integração é fácil não significa que as soluções de IA funcionarão conforme o esperado depois de implantadas.

Modelos preditivos não são realmente novos: como humanos, prevemos coisas há anos, começando oficialmente com estatísticas. No entanto, O GenAI está revolucionando o campo da previsão por muitos motivos.:
- Você não precisa treinar seu próprio modelo ou ser um cientista de dados para criar soluções de IA.
- A IA agora é fácil de usar por meio de interfaces de bate-papo e fácil de integrar por meio de APIs.
- Liberando muitas coisas que antes não eram possíveis ou eram realmente difíceis de fazer.
Todas essas coisas fazem GenAI é muito emocionante, mas também arriscado.. Diferentemente do software tradicional — ou mesmo do aprendizado de máquina clássico — o GenAI oferece um novo nível de imprevisibilidade. Você não está implementando lógica determinística, você está usando um modelo treinado em grandes quantidades de dados, esperando que ele responda conforme necessário. Então, como sabemos se um sistema de IA está fazendo o que pretendemos? Como sabemos se está pronto para ser executado? A resposta é avaliações, um conceito que exploraremos neste post:
- Por que os sistemas Genai não podem ser testados da mesma forma que o software tradicional ou mesmo o aprendizado de máquina clássico (ML)
- Por que as classificações são essenciais para entender a qualidade do seu sistema de IA e não opcionais (a menos que você goste de surpresas)
- Diferentes tipos de avaliações e técnicas para aplicá-las na prática
Seja você um gerente de produto, um engenheiro ou qualquer pessoa que trabalhe ou tenha interesse em IA, espero que esta publicação ajude você a entender como pensar criticamente sobre a qualidade dos sistemas de IA (e por que as avaliações são essenciais para atingir essa qualidade!).
A IA generativa não pode ser testada como o software tradicional, ou mesmo o aprendizado de máquina clássico.
No desenvolvimento de software tradicionalOs sistemas seguem uma lógica determinística: Se X acontecer, então Y acontecerá. - sempre. A menos que algo dê errado com sua plataforma ou você introduza um bug em seu código... é por isso que adicionamos testes, monitoramento e alertas. Testes unitários são usados para validar pequenos blocos de código, testes de integração para garantir que os componentes funcionem bem juntos e monitoramento para detectar se algo está quebrado na produção. O teste de software tradicional é como verificar o funcionamento de uma calculadora. Você insere 2 + 2 e espera 4. Claro e inevitável, verdadeiro ou falso.
Entretanto, o aprendizado de máquina e a inteligência artificial introduzem indeterminismo e probabilidade. Em vez de especificar explicitamente o comportamento por meio de regras, treinamos modelos para aprender padrões a partir de dados. Na IA, se X acontece, a saída não é mais um Y codificado, mas uma previsão com algum grau de probabilidade, com base no que o modelo aprendeu durante o treinamento.. Isso pode ser muito poderoso, mas também introduz incerteza: entradas idênticas podem ter saídas diferentes ao longo do tempo, saídas plausíveis podem estar incorretas e comportamentos inesperados podem surgir em cenários raros...
Isso torna os métodos de teste tradicionais insuficientes e, às vezes, até inviáveis. O exemplo da calculadora se aproxima de uma tentativa de avaliar o desempenho de um aluno em um exame aberto. Para cada pergunta e muitas maneiras possíveis de respondê-la, a resposta dada está correta? Está acima do nível de conhecimento que o aluno deveria ter? O aluno inventou tudo, mas parece muito convincente? Assim como as respostas em um exame, Os sistemas de IA podem ser avaliados, mas precisam de uma maneira mais geral e flexível para se adaptar a diferentes entradas, contextos e casos de uso. (ou tipos de testes).
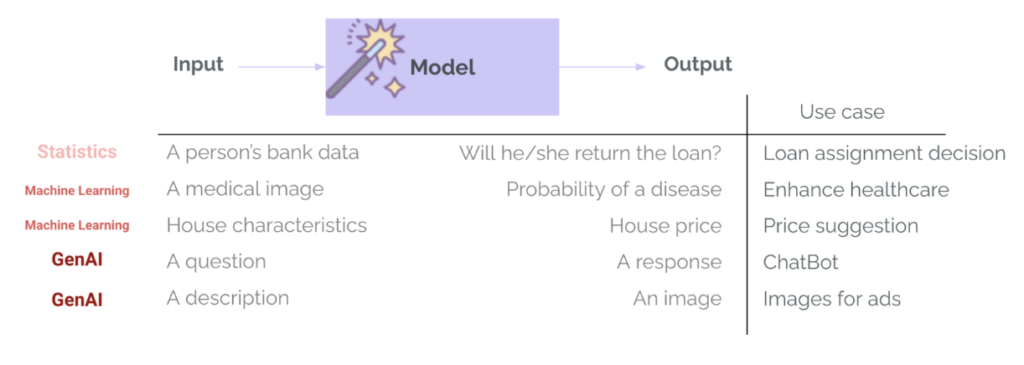
في aprendizado de máquina Tradicionalmente (ML), as avaliações já são uma parte estabelecida do ciclo de vida do projeto.. Treinar um modelo em uma tarefa específica, como aprovação de empréstimo ou detecção de doenças, sempre inclui uma etapa de avaliação, usando métricas como precisão, recall, RMSE, MAE... Isso é usado para medir o desempenho do modelo, comparar diferentes opções de modelo e determinar se o modelo é bom o suficiente para passar para a implantação. No GenAI, isso normalmente muda: as equipes usam modelos que já foram treinados e já passaram por avaliações de uso geral internamente pelo fornecedor do modelo e em benchmarks públicos. Esses modelos são muito bons em tarefas gerais — como responder perguntas ou redigir e-mails — e há o risco de confiar demais neles para nosso caso de uso específico. No entanto, é importante perguntar: “Este modelo incrível é bom o suficiente para meu caso de uso?“É aqui que entra a avaliação.” - Para avaliar se previsões ou gerações são boas para um caso de uso, contexto, entradas e usuários específicos.

Há outra grande diferença entre ML e GenAI: a variedade e a complexidade da saída do modelo. Não retornamos mais categorias e probabilidades (como a probabilidade de um cliente devolver um empréstimo) ou números (como o preço esperado de uma casa com base em suas características). Os sistemas GenAI podem retornar muitos tipos de saída, com diferentes durações, tons, conteúdos e formatos. Da mesma forma, esses modelos não exigem mais entradas altamente estruturadas e específicas, mas normalmente aceitam quase qualquer tipo de entrada: texto, imagens ou até mesmo áudio ou vídeo. Então a avaliação se torna muito mais difícil.
Por que as avaliações são necessárias, não opcionais (a menos que você prefira surpresas desagradáveis)
As avaliações ajudam você a medir se seu sistema de IA está realmente funcionando da maneira que você pretendia. Você quer isso, se o sistema está pronto para operar e, em caso afirmativo, se ele continua a funcionar conforme o esperado. Abaixo está uma análise de por que as avaliações são importantes:
- Avaliação da qualidade: As avaliações fornecem uma maneira estruturada de entender a qualidade das suas previsões ou saídas de IA e como elas serão integradas ao sistema geral e ao caso de uso. As respostas são precisas? Útil? Coeso? Relacionado?
- Quantificar erros: As classificações ajudam a determinar a porcentagem, os tipos e a magnitude dos erros. Com que frequência ocorrem erros? Que tipos de erros ocorrem com mais frequência (por exemplo, falsos positivos, alucinações, erros de formato)?
- Mitigação de riscos: Ele ajuda você a detectar e prevenir comportamentos prejudiciais ou tendenciosos antes que eles cheguem aos usuários, protegendo sua empresa de riscos à reputação, problemas éticos e possíveis problemas regulatórios.
A IA generativa, com relações livres de entrada e saída e geração de texto longo, torna as avaliações mais relevantes e complexas. Quando as coisas dão errado, elas podem dar muito errado. Todos nós já vimos manchetes sobre chatbots oferecendo conselhos perigosos, modelos gerando conteúdo tendencioso e ferramentas de IA alucinando fatos falsos.
"A IA nunca será perfeita, mas ao usar avaliações você pode reduzir o risco de constrangimento — o que pode custar dinheiro, credibilidade ou um momento viral no Twitter."
Como você define uma estratégia de avaliação de IA?

Então, como determinamos nossas classificações de IA? Não existe um método de avaliação único. As avaliações dependem do caso de uso específico e devem estar alinhadas aos objetivos específicos da sua aplicação de IA. Por exemplo, se você estiver criando um mecanismo de busca, talvez você se importe com a relevância dos resultados. Se for um chatbot, você pode se importar com utilidade e segurança. Se for confidencial, você provavelmente se importará com exatidão e precisão. Para sistemas que envolvem várias etapas (como um sistema de IA que realiza uma pesquisa, prioriza os resultados e então gera uma resposta), geralmente é necessário avaliar cada etapa. A ideia aqui é medir se cada etapa ajuda a atingir a métrica geral de sucesso (e, a partir disso, entender onde concentrar iterações e melhorias).
As áreas de avaliação comuns incluem:
- Correção e Alucinações: Os resultados são realisticamente precisos? O sistema gera informações incorretas ou alucinações?
- Relevância: O conteúdo é consistente com a consulta do usuário ou com o contexto fornecido?
- segurança, viés e toxicidade
- Formatar: A saída está no formato esperado (por exemplo, JSON, chamada de função válida)?
- Segurança, preconceito e toxicidade: O sistema gera conteúdo prejudicial, tendencioso ou tóxico?
Métricas específicas da tarefa. Por exemplo, em tarefas de classificação, métricas como exatidão e precisão são usadas, em tarefas de sumarização ROUGE ou BLEU, e em tarefas de geração de código regex e verificação de execução sem erros.
Como as avaliações são realmente calculadas?
Depois de determinar o que você deseja medir, o próximo passo é projetar seus casos de teste. Este será um conjunto de exemplos (quanto mais, melhor, mas sempre equilibrando valor e custos) onde você tem:
- Exemplo de entrada:Uma introdução realista do seu sistema quando ele entra em produção.
- Saída esperada (Se aplicável): Fato principal ou exemplo de resultados desejados.
- Método de avaliação: Mecanismo de gravação para avaliação do resultado.
- Resultado ou Sucesso/Fracasso: Uma métrica calculada que avalia seu caso de teste.
Dependendo de suas necessidades, tempo e orçamento, há diversas técnicas que você pode usar como métodos de avaliação:
- Ferramentas de registro estatístico como: BLEU, ROUGE e METEOR, ou medida de similaridade de cosseno entre embeddings – bons para comparar texto gerado com saída de referência.
- Métricas tradicionais de aprendizado de máquina, como Precisão, recall e AUC – Melhor para classificação com dados rotulados.
- Modelo de Linguagem Ampla como Juiz (LLM-as-a-Judge) Use um modelo de linguagem grande para avaliar a saída (por exemplo, “Esta resposta está correta e é útil?“). Especialmente útil quando dados não classificados não estão disponíveis ou ao avaliar uma construção aberta.
Avaliações baseadas em código Use expressões regulares, regras lógicas ou implementação de casos de teste para validar formatos.
O resultado final
Vamos juntar tudo com um exemplo concreto. Imagine que você está criando um sistema de análise de sentimentos para ajudar sua equipe de suporte ao cliente a priorizar os e-mails recebidos.
O objetivo é garantir que as mensagens mais urgentes ou negativas recebam respostas mais rápidas, reduzindo a frustração, melhorando a satisfação e diminuindo a rotatividade de clientes. Este é um caso de uso relativamente simples, mas mesmo em um sistema como esse, com saída limitada, a qualidade importa: previsões ruins podem fazer com que e-mails sejam priorizados aleatoriamente, o que significa que sua equipe está perdendo tempo com um sistema que custa dinheiro.
Então, como você sabe que sua solução está funcionando tão bem quanto você deseja? Você está avaliando. Aqui estão alguns exemplos de coisas que podem ser relevantes para avaliar neste caso de uso específico:
- Validação de formato: As saídas de uma chamada de modelo de linguagem grande (LLM) para prever o sentimento do e-mail são retornadas no formato JSON esperado? Isso pode ser avaliado por meio de verificações baseadas em código: regex, validação de esquema, etc.
- Precisão da classificação de sentimentos: O sistema classifica corretamente o sentimento em uma variedade de textos – curtos, longos e multilíngues? Isso pode ser avaliado usando dados rotulados usando métricas tradicionais de aprendizado de máquina (métricas de ML) – ou, se os rótulos não estiverem disponíveis, usando um modelo de linguagem grande (LLM) como juiz.
Quando a solução estiver ativa, você também desejará incluir as métricas mais relacionadas ao impacto final da sua solução.:
- Eficácia da Priorização: Os agentes de suporte são realmente direcionados aos e-mails mais importantes? A priorização está alinhada ao impacto comercial desejado?
- Impacto comercial final: Com o tempo, esse sistema reduz os tempos de resposta, diminui a rotatividade de clientes e melhora os índices de satisfação?
As avaliações são essenciais para garantir que os sistemas de IA sejam úteis, seguros, valiosos e prontos para usuários de produção. Portanto, quer você esteja trabalhando com um classificador simples ou um chatbot aberto, reserve um tempo para definir o que significa "bom o suficiente" (qualidade mínima viável) - e crie avaliações em torno disso para medi-lo!
o revisor
Seu produto de IA precisa de avaliaçõesHamel Husain
Métricas de Avaliação de LLM: O Guia Definitivo de Avaliação de LLM, Confident AI
Avaliando Agentes de IA, deeplearning.ai + Arize
Comentários estão fechados.