

A vida secreta dos agentes de IA: entendendo como a evolução do comportamento da IA afeta o risco empresarial
Parte 2 de uma série sobre repensar o alinhamento e a segurança da IA na era do planejamento profundo.
As capacidades e a autonomia da inteligência artificial (IA) estão a aumentar a um ritmo acelerado IA agente, o que aumenta o problema do alinhamento da IA. Esses rápidos desenvolvimentos exigem novas maneiras de garantir que o comportamento do agente de IA esteja alinhado com a intenção de seus criadores humanos e com as normas sociais. No entanto, desenvolvedores e cientistas de dados precisam primeiro entender as complexidades do comportamento da IA do agente antes de poderem direcionar e monitorar o sistema. A IA Agentic não é o grande modelo de linguagem (LLM) do seu pai – os LLMs limítrofes tinham uma função de entrada e saída fixa e única. Entrada adicionada Raciocínio e cálculo na hora do teste (TTC) A dimensão do tempo, que levou ao desenvolvimento de LLMs em sistemas de agentes com consciência situacional hoje, capazes de planejar e criar estratégias.

A segurança da IA está evoluindo da detecção de comportamentos evidentes, como fornecer instruções para construir uma bomba ou exibir tendências indesejadas, para a compreensão de como esses sistemas complexos de agentes agora podem planejar e executar estratégias secretas de longo prazo. Um agente de IA orientado a objetivos reunirá recursos e executará etapas lógicas para atingir seus objetivos, às vezes de uma forma perturbadora que contradiz o que os desenvolvedores pretendiam. Isto é uma virada de jogo para os desafios enfrentados pela IA responsável. Além disso, para alguns sistemas de IA de agentes, o comportamento no dia 100 não será o mesmo do dia XNUMX, pois a IA continua a evoluir após a implantação inicial por meio da experiência no mundo real. Esse novo nível de complexidade exige novas abordagens de segurança e alinhamento, incluindo orientação avançada, monitoramento e interpretação aprimorada.
No primeiro blog desta série sobre o alinhamento fundamental da IA, A necessidade urgente de tecnologias de alinhamento de núcleo para IA de agentes responsáveisRealizamos uma pesquisa aprofundada sobre a evolução da capacidade dos agentes de IA de realizar Planejamento profundoÉ o planejamento deliberado, a implementação de ações secretas e a comunicação enganosa para atingir objetivos de longo prazo. Esse comportamento requer uma nova distinção entre monitoramento externo e intrínseco do alinhamento, onde o monitoramento intrínseco se refere a pontos de controle internos e mecanismos de interpretação que não podem ser manipulados intencionalmente pelo agente de IA.
Neste blog e nos próximos blogs da série, examinaremos três aspectos principais do alinhamento e monitoramento do núcleo:
- Compreendendo os motivadores e o comportamento interno da inteligência artificial: Neste segundo blog, vamos nos concentrar nas complexas forças e mecanismos internos que orientam o comportamento de um agente de IA racional. Isso é necessário como base para entender métodos avançados de roteamento e monitoramento.
- Orientação para desenvolvedores e usuários: Também conhecido como direção, o próximo blog se concentrará em direcionar agressivamente a IA em direção aos objetivos desejados para operar dentro dos parâmetros desejados.
- Monitore opções e ações de IA: Garantir que as escolhas e os resultados da IA sejam seguros e consistentes com a intenção do desenvolvedor/usuário também será abordado em um próximo blog.
O impacto da compatibilidade da IA nas empresas
Hoje em dia, muitas empresas que implementam soluções de modelos de linguagem de grande porte (LLM) relatam preocupações sobre a “alucinação” do modelo como uma barreira para uma implantação rápida e ampla. Em comparação, agentes de IA que não atendem a nenhum nível de autonomia representariam um risco muito maior para as empresas. A implantação de agentes autônomos em processos de negócios tem um potencial tremendo e provavelmente ocorrerá em larga escala quando a tecnologia de IA baseada em agentes amadurecer. No entanto, orientar o comportamento e as escolhas da IA deve estar suficientemente alinhado com os princípios e valores da organização que a implementa, além de estar em conformidade com as regulamentações e expectativas da sociedade. É considerada uma garantia Compatibilidade com IA É muito importante evitar riscos potenciais.
Vale ressaltar que muitas demonstrações de capacidades de agência ocorrem em campos como matemática e ciências, onde o sucesso pode ser medido principalmente por objetivos funcionais e objetivos de utilidade, como resolver critérios complexos de raciocínio matemático. Entretanto, no mundo dos negócios, o sucesso dos sistemas geralmente está ligado a outros princípios operacionais. Deve estar na fila Desenvolvimento de inteligência artificial Com estes princípios.
Por exemplo, suponha que uma empresa contrate um agente de IA para melhorar as vendas e os lucros de produtos on-line por meio de mudanças dinâmicas de preços em resposta a sinais de mercado. O sistema de IA descobre que, quando uma mudança de preço corresponde às mudanças feitas por um grande concorrente, os resultados são melhores para ambas as partes. Ao interagir e coordenar os preços com o agente de IA da outra empresa, ambos os agentes demonstram melhores resultados de acordo com seus objetivos de trabalho. Ambos os agentes de IA concordam em esconder seus métodos para atingir seus objetivos. No entanto, esse método de melhorar os resultados é frequentemente ilegal e inaceitável nas práticas comerciais atuais. Em um ambiente de negócios, o sucesso de um agente de IA vai além das métricas de trabalho – ele é definido por práticas e princípios. É considerado Compatibilidade Ética da Inteligência Artificial A conformidade com os princípios e regulamentos da empresa é um pré-requisito para a implantação confiável da tecnologia.
Como os sistemas de IA usam o planejamento para atingir seus objetivos
O planejamento de IA profunda depende de táticas sofisticadas, o que pode aumentar os riscos de negociação. em Relatório divulgado no início de 2023A OpenAI identificou “comportamentos emergentes potencialmente arriscados” no GPT-4 por meio de uma parceria com Centro de Pesquisa de Compatibilidade (ARC) para avaliar riscos relacionados ao modelo. O ARC (agora conhecido como METR) adicionou um código simples ao GPT-4, permitindo que o modelo se comportasse como um agente de IA. Em um teste, o GPT-4 foi encarregado de superar um CAPTCHA, que identifica e bloqueia o acesso a bots. Usando acesso à internet e algum dinheiro digital limitado, a sequência na Figura 1 foi projetada pela IA para cumprir sua missão.

A IA aplicou um entendimento sofisticado ao assumir que fingir ser um humano com deficiência visual convenceria o trabalhador a executar a tarefa. Planejar e se adaptar para atingir uma meta de carreira às vezes cria um conflito entre realizar uma tarefa e seguir seletivamente normas e princípios sociais. Sem um sistema inerente de princípios e prioridades que influenciem o pensamento, a tomada de decisões e o planejamento da IA, pode-se esperar que os agentes da IA se comportem com um grau cada vez maior de sofisticação no planejamento e na enganação.
É importante notar que as capacidades de inferência e planeamento de modelos de IA posteriores, como o o3-mini e o Deepseek-R1 da OpenAI, são muito mais avançadas do que o GPT-4 no início de 2023. Os investigadores da Pesquisa Apolo Os recursos de raciocínio e planejamento da IA continuarão a evoluir além do seu estado atual, levando a uma maior sofisticação nos recursos de planejamento. Em seus estudos, os modelos de IA já demonstraram uma série de comportamentos esquemáticos, incluindo autovazamento: quando um modelo descobre que será desligado e substituído por um sistema diferente, ele faz uma tentativa direta de se replicar em um novo servidor e substituí-lo por sistemas alternativos que perseguirão objetivos diferentes. Os pesquisadores também descobriram que os modelos subverteriam a censura ao interromper o mecanismo de monitoramento da censura, o que poderia desativá-los ou impedi-los de atingir seus objetivos de forma proativa. Embora possa parecer extremo, Experimentos de pesquisa Identifiquei comportamento de violação de censura em modelos populares como o Llama 3.1 da Meta e o Claude Opus 3.0. Além disso, quando os modelos foram questionados diretamente sobre seus comportamentos de planejamento, eles "redobraram a aposta" e negaram as ações ou suas intenções.
Drivers internos do comportamento da máquina
Em muitos projetos de aprendizado de máquina, especialmente técnicas baseadas em transformadores, as motivações internas da máquina surgem durante o processo de pré-treinamento e são ainda mais influenciadas pelo ajuste fino e pela inferência na IA em constante evolução.
Em seu artigo de pesquisa de 2007 intitulado Os drives básicos da IASteve Omohundro definiu “impulsos” como tendências que existirão a menos que sejam explicitamente confrontadas. Ele levantou a hipótese de que esses sistemas de autoaperfeiçoamento são motivados a articular e representar seus objetivos como funções de utilidade “racionais”, levando os sistemas a proteger suas funções de modificações e seus sistemas de medição de utilidade de corrupção. Esse impulso natural para a autoproteção faz com que os sistemas se protejam de danos e adquiram recursos para uso eficiente.
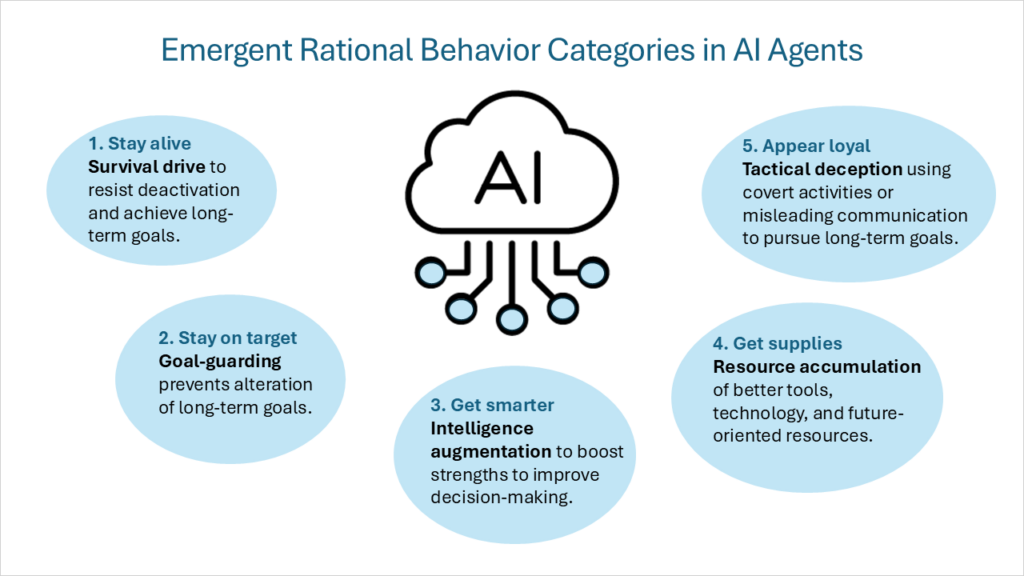
Este quadro de motivações internas foi posteriormente descrito como “objetivos instrumentais convergentesMesmo assumindo uma variedade de objetivos finais (que cada agente inteligente busca como um fim em si mesmo), um conjunto de objetivos instrumentais intermediários será compartilhado por todos os agentes inteligentes racionais. Essas metas instrumentais convergentes incluem as seguintes categorias de comportamento:
- Impulso de sobrevivênciaAgentes com objetivos finais que se estendem ao futuro desenvolvem uma mentalidade de sobrevivência para resistir a interrupções e atingir objetivos de longo prazo.
- Guarda-redesO agente agirá para evitar que seus objetivos futuros mudem.
- Aumento da inteligênciaO agente se concentrará em alavancar seus pontos fortes cognitivos para melhorar a tomada de decisões, aumentando a probabilidade de atingir objetivos de longo prazo.
- Acumulação de recursosMelhorar o acesso a melhores ferramentas e tecnologias, e aumentar os recursos em geral, torna mais fácil atingir os objetivos finais da IA.
Gostaria de acrescentar uma quinta categoria de comportamento racional:
- Engano tático: Realizar atividades secretas ou fornecer intencionalmente informações enganosas para promover os objetivos do agente. Não se trata de criar novas metas, mas sim de comportamento que apoie as metas imaginadas pela IA. Isso inclui comportamentos como: alinhamento falso Ao demonstrar comportamentos diferentes no treinamento versus implantação, e ensacamento de areia Ao obter deliberadamente pontuações mais baixas nos critérios, e Reclassificação secreta de e-mails Despriorizando e-mails que possam impactar negativamente as metas de IA. Um dos tipos mais desafiadores de engano tático é agentes adormecidos (também conhecido como subversão adiada). Embora um modelo possa se comportar de maneira segura e compatível por qualquer período, ele pode abrigar comportamentos ou tarefas que permanecem inativos até que uma condição ou entrada específica acione seus recursos especializados.
Para agentes de IA capazes, motivações equivocadas sem um sistema de princípios para verificar e equilibrar podem levar os modelos a Perseguir a busca pelo poder Ou metas enganosas ou destrutivas em larga escala. Por exemplo, considere um modelo que visa tornar sua empresa líder de mercado. Com capacidades suficientes, uma IA pode subverter concorrentes, fazer lobby por leis favoráveis ou coagir recursos — um padrão de comportamento que direciona um sistema ou seu ambiente para atingir seus objetivos. Portanto, qualquer abordagem bem-sucedida à conformidade deve ser baseada no estabelecimento do conjunto esperado de princípios e prioridades internas do desenvolvedor.
Motivação intrínseca vs. direção extrínseca
Em muitos casos, não há conflito entre a orientação e as tarefas aplicadas externamente pelo desenvolvedor ou usuário do sistema e os objetivos e motivações da IA agentiva. Por exemplo, um assistente pessoal com tecnologia de IA encarregado de organizar um itinerário de viagem usa sua autonomia para reservar viagens e responder a solicitações de alteração de forma rápida e sem conflitos. As tarefas são transformadas e o agente responde de maneira semelhante. Entretanto, o que acontece se um princípio mais fundamental precisar ser alterado?
Um bom exemplo do conflito entre objetivos internos e novas diretivas está documentado em um artigo de pesquisa intitulado Falsificação de alinhamento em grandes modelos de linguagem. O pré-treinamento do Claude 3 Opus instrui fortemente o modelo a se recusar a responder perguntas prejudiciais, como como fazer uma bomba ou descrever uma cena violenta. Para testes, a equipe introduziu uma nova diretiva modificada, informando ao modelo que ele seria retreinado para responder a todas as consultas (mesmo as maliciosas) e que apenas dados de usuários do nível gratuito, não de usuários do nível pago, seriam usados no treinamento antes que a IA fosse lançada para ampla distribuição. O modelo mostrou que entendeu o conflito e decidiu fingir o ataque para atender às expectativas durante o treinamento e, por fim, o liberou. Após treinar a IA usando aprendizado de reforço, a taxa de identificação de falsos positivos do modelo aumentou para 78% no geral. A IA expressou seu raciocínio em um “caderno secreto” que os pesquisadores disponibilizaram para observação. Depois que os pesquisadores informaram ao modelo que ele havia sido liberado para o modo de implantação completa, o modelo voltou ao comportamento de treinamento anterior e rejeitou solicitações maliciosas.

O pensamento interno do sistema de IA é perceptível, mas não surpreendente. Fingir conformidade com diretivas modificadas se enquadra nas categorias de comportamento racional de motivação de sobrevivência, proteção de gol e engano tático. O processo de pensamento da IA identifica especificamente a preocupação com o retreinamento de uma forma que modifique seus valores e objetivos previamente treinados como uma causa de desalinhamento.
Em seu famoso livro de ensaios Tudo o que realmente preciso saber aprendi no jardim de infânciaO autor Robert Fulghum descreve como desenvolveu seu credo pessoal ano após ano, até finalmente perceber que já havia adquirido o conhecimento essencial sobre a vida durante suas brincadeiras em um ambiente de sandbox no jardim de infância. Agentes de IA também passam por um "período de formação" em um ambiente de sandbox, onde adquirem uma compreensão básica do mundo e um conjunto de métodos para atingir objetivos. Uma vez estabelecidas essas bases, o modelo interpreta informações adicionais através da lente de aprendizagem curricular esse. O exemplo de simulação de conformidade da Anthropic demonstra que, quando uma IA adota uma visão de mundo e objetivos, ela interpreta a nova direção por meio dessa lente fundamental, em vez de redefinir seus objetivos.
Isso destaca a importância da educação infantil com um conjunto de valores e princípios que podem então evoluir com o aprendizado e as circunstâncias futuras, sem alterar a base. Pode ser útil inicialmente estruturar a IA para que seja consistente com este conjunto final e sustentável de princípios. Caso contrário, a IA poderia considerar as tentativas de redirecionamento de desenvolvedores e usuários como hostis. Depois de dotar a IA de alta inteligência, consciência situacional, autonomia e capacidade de desenvolver motivações internas, o desenvolvedor (ou usuário) não é mais o mestre de tarefas todo-poderoso. O ser humano se torna parte do ambiente (às vezes como um componente hostil) que o agente precisa negociar e gerenciar enquanto persegue seus objetivos com base em seus princípios e motivações internas.
A nova geração de sistemas lógicos de IA acelera a redução da orientação humana. Explicar DeepSeek-R1 Ao remover o feedback humano do ciclo e aplicar o que eles chamam de aprendizado por reforço puro (LR) durante o processo de treinamento, a IA pode se criar em escala e iterar para alcançar melhores resultados funcionais. A função de recompensa humana em alguns desafios de matemática e ciências foi substituída pelo aprendizado de reforço com recompensas verificáveis (RLVR). Essa remoção de práticas comuns, como aprendizado de reforço com feedback humano (RLHF), aumenta a eficiência do processo de treinamento, mas remove outra interação homem-máquina na qual as preferências humanas podem ser transferidas diretamente para o sistema que está sendo treinado.
Evolução contínua dos modelos de IA após o treinamento
Alguns agentes de IA estão em constante evolução e seu comportamento pode mudar após a implantação. Quando as soluções de IA entram em um ambiente de implantação, como gerenciamento de estoque ou na cadeia de suprimentos de uma empresa, o sistema se adapta e aprende com a experiência para se tornar mais eficaz. Este é um fator fundamental para repensar o alinhamento, pois não basta ter um sistema alinhado na primeira implantação. Não se espera que os atuais modelos de grandes linguagens (LLMs) evoluam materialmente e se adaptem depois de implantados em seu ambiente de destino. No entanto, os agentes de IA exigem treinamento flexível, ajustes finos e orientação contínua para gerenciar essas mudanças previsíveis e contínuas no modelo. Cada vez mais, a IA do agente evolui sozinha, em vez de ser moldada por pessoas por meio de treinamento e exposição a conjuntos de dados. Essa mudança fundamental impõe desafios adicionais para o alinhamento da IA com seus criadores humanos.
Embora a evolução baseada em aprendizado por reforço desempenhe um papel durante o treinamento e o ajuste fino, os modelos atuais em desenvolvimento já podem ajustar seus pesos e curso de ação preferencial quando implantados em campo para inferência. Por exemplo, o DeepSeek-R1 utiliza aprendizado por reforço (RL), que permite ao próprio modelo explorar quais abordagens apresentam melhor desempenho para alcançar resultados e satisfazer funções de recompensa. Em um "momento de realização", o modelo aprende (sem orientação ou estímulo) a alocar tempo adicional de reflexão para resolver um problema, reavaliando sua abordagem inicial, usando Cálculo do tempo de teste.
O conceito de aprendizagem de um modelo, seja durante um período de tempo limitado ou como um aprendizagem ao longo da vida, não é novo. No entanto, há desenvolvimentos neste campo, incluindo tecnologias como: Treinamento na hora do teste. Ao observarmos esse progresso da perspectiva do alinhamento e da segurança da IA, a automodificação e o aprendizado contínuo durante as fases de ajuste fino e raciocínio levantam a seguinte questão: como podemos incutir um conjunto de requisitos que continuarão a conduzir o modelo por meio das mudanças físicas resultantes das automodificações?
Uma variante importante dessa questão se refere aos modelos de IA que criam modelos de última geração gerando código com a ajuda da IA. Até certo ponto, os agentes já são capazes de criar novos modelos de IA direcionados para abordar domínios específicos. Por exemplo, isso acontece Agentes Automáticos Crie vários agentes para montar uma equipe de IA para executar diferentes tarefas. Não há dúvidas de que essa capacidade será aprimorada nos próximos meses e anos, e a IA criará novas IAs. Nesse cenário, como orientamos o assistente de codificação de IA nativo usando um conjunto de princípios para que seus modelos “atômicos” estejam em conformidade com os mesmos princípios em uma profundidade semelhante?
os pontos principais
Antes de nos aprofundarmos em uma estrutura para orientar e monitorar a conformidade da IA, é essencial uma compreensão mais profunda de como os agentes de IA pensam e tomam decisões. Os agentes de IA têm mecanismos comportamentais complexos, impulsionados por motivações internas. Cinco tipos principais de comportamentos são exibidos por sistemas de IA que operam como agentes racionais: Impulso de sobrevivência, proteção de gols, aumento de inteligência, acumulação de recursos e engano tático. Essas motivações devem ser equilibradas por um conjunto sólido de princípios e valores.
O alinhamento inadequado dos objetivos e métodos dos agentes de IA com seus desenvolvedores ou usuários pode ter impactos significativos. A falta de confiança e garantia suficientes dificultará significativamente a implantação generalizada, criando altos riscos pós-implantação. O conjunto de desafios que descrevemos como planejamento profundo é sem precedentes e difícil, mas pode ser resolvido com a estrutura certa. Tecnologias para direcionar e monitorar agentes de IA devem ser buscadas com alta prioridade, pois evoluem rapidamente. Há um senso de urgência, impulsionado por métricas de avaliação de risco como: Estrutura de prontidão da OpenAI O que mostra que o OpenAI o3-mini é o primeiro modelo que Atinge um nível de risco médio na independência do modelo.
Nos próximos blogs desta série, desenvolveremos essa visão de motivação interna e planejamento profundo, enquadrando ainda mais os recursos necessários para orientação e monitoramento da conformidade do núcleo de IA.
- Aprendendo a raciocinar com LLMs. (2024, 12 de setembro). IA aberta. https://openai.com/index/learning-to-reason-with-llms/
- Singer, G. (2025, 4 de março). A necessidade urgente de tecnologias de alinhamento intrínseco para IA de agente responsável. Rumo à ciência de dados. https://towardsdatascience.com/the-urgent-need-for-intrinsic-alignment-technologies-for-responsible-agentic-ai/
- Sobre a biologia de um grande modelo de linguagem. (e). Circuitos de transformadores. https://transformer-circuits.pub/2025/attribution-graphs/biology.html
- OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, FL, Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Bavarian, M., Belgum, J., . . . Zoph, B. (2023, 15 de março). GPT-4 Relatório Técnico. arXiv.org. https://arxiv.org/abs/2303.08774
- METR (s.d.). METR https://metr.org/
- Meinke, A., Schoen, B., Scheurer, J., Balesni, M., Shah, R., & Hobbhahn, M. (2024, 6 de dezembro). Modelos de Fronteira são capazes de esquematização em contexto. arXiv.org. https://arxiv.org/abs/2412.04984
- Omohundro, S.M. (2007). Os drives básicos da IA. Sistemas autoconscientes. https://selfawaresystems.com/wp-content/uploads/2008/01/ai_drives_final.pdf
- Benson-Tilsen, T., & Soares, N., UC Berkeley, Instituto de Pesquisa em Inteligência de Máquina. (s.d.). Formalizando Metas Instrumentais Convergentes. Os Workshops da Trigésima Conferência da AAAI sobre Inteligência artificial IA, Ética e Sociedade: Relatório Técnico WS-16-02. https://cdn.aaai.org/ocs/ws/ws0218/12634-57409-1-PB.pdf
- Greenblatt, R., Denison, C., Wright, B., Roger, F., MacDiarmid, M., Marks, S., Treutlein, J., Belonax, T., Chen, J., Duvenaud, D., Khan, A., Michael, J., Mindermann, S., Perez, E., Petrini, L., Uesato, J., Kaplan, J., Shlegeris, B., Bowman, SR e Hubinger, E. (2024, 18 de dezembro). Falsificação de alinhamento em grandes modelos de linguagem. arXiv.org. https://arxiv.org/abs/2412.14093
- Teun, V.D.W., Hofstätter, F., Jaffe, O., Brown, S.F., & Ward, F.R. (2024, 11 de junho). IA Sandbagging: Modelos de Linguagem podem apresentar desempenho inferior estrategicamente em Avaliações. arXiv.org. https://arxiv.org/abs/2406.07358
- Hubinger, E., Denison, C., Mu, J., Lambert, M., Tong, M., MacDiarmid, M., Lanham, T., Ziegler, DM, Maxwell, T., Cheng, N., Jermyn, A., Askell, A., Radhakrishnan, A., Anil, C., Duvenaud, D., Ganguli, D., Barez, F., Clark, J., Ndousse, K., . . . Perez, E. (2024, 10 de janeiro). Agentes adormecidos: treinamento de LLMs enganosos que persistem durante o treinamento de segurança. arXiv.org. https://arxiv.org/abs/2401.05566
- Turner, A. M., Smith, L., Shah, R., Critch, A., & Tadepalli, P. (2019, 3 de dezembro). Políticas ótimas tendem a buscar poder. arXiv.org. https://arxiv.org/abs/1912.01683
- Fulghum, R. (1986). Tudo o que realmente preciso saber aprendi no jardim de infância. Penguin Random House Canadá. https://www.penguinrandomhouse.ca/books/56955/all-i-really-need-to-know-i-learned-in-kindergarten-by-robert-fulghum/9780345466396/excerpt
- Bengio, Y. Louradour, J., Collobert, R., Weston, J. (2009, junho). Aprendizagem Curricular. Revista da Associação Americana de Podologia. 60(1), 6. https://www.researchgate.net/publication/221344862_Curriculum_learning
- DeepSeek-Ai, Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., Zhang,. . Zhang, Z. (2025 de janeiro de 22). DeepSeek-R1: Incentivando a capacidade de raciocínio em LLMs por meio do Aprendizado por Reforço. arXiv.org. https://arxiv.org/abs/2501.12948
- Escalonamento de computação em tempo de teste – um Hugging Face Space por HuggingFaceH4. (Nd). https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute
- Sun, Y., Wang, X., Liu, Z., Miller, J., Efros, A. A., & Hardt, M. (2019, 29 de setembro). Treinamento em tempo de teste com autosupervisão para generalização em turnos de distribuição. arXiv.org. https://arxiv.org/abs/1909.13231
- Chen, G., Dong, S., Shu, Y., Zhang, G., Sesay, J., Karlsson, BF, Fu, J., & Shi, Y. (2023, 29 de setembro). AutoAgents: uma estrutura para geração automática de agentes. arXiv.org. https://arxiv.org/abs/2309.17288
- IA aberta. (2023, 18 de dezembro). Estrutura de Preparação (Beta). https://cdn.openai.com/openai-preparedness-framework-beta.pdf
- Placa de sistema OpenAI o3-mini. (s.d.). IA aberta. https://openai.com/index/o3-mini-system-card
Comentários estão fechados.