
Como instalar os modelos de linguagem de grande porte (LLMs) mais recentes localmente em um Mac.

Nos últimos anos, os Modelos de Linguagem de Grande Porte (LLMs, na sigla em inglês) tornaram-se cada vez mais populares devido à sua capacidade de gerar texto semelhante ao humano e auxiliar em diversas tarefas. Nem todos os modelos são de código aberto, mas quase todas as grandes empresas de tecnologia possuem uma versão que os usuários podem baixar e executar.

Executar esses modelos localmente no seu Mac pode ser vantajoso tanto por questões de privacidade quanto de custo. Neste artigo, exploraremos como instalar e executar LLMs usando o Mac. OllamaÉ uma ferramenta poderosa para desenvolvedores e usuários iniciantes, e discutiremos algumas ferramentas de interface gráfica que podem simplificar o processo para aqueles que preferem não usar o Terminal do macOS.
Dessa forma, você pode acessar os modelos de texto mais recentes com tecnologia de IA do [Google], [Microsoft], [Meta] e de outras empresas de IA, como [Mistral] e [DeepSeek].
Entendendo os LLMs: O que significam os parâmetros?
Antes de mergulharmos no processo de instalação, vamos esclarecer o que significam números como “7B"Ou"14BAo se referir a LLMs, esses números representam o tamanho do modelo em termos de os professores (Em bilhões), que são essencialmente “alças e interruptores” que são ajustados com precisão durante o treinamento.
Um número maior de parâmetros permite que o modelo capture padrões e relações mais complexos na linguagem, o que pode levar a um melhor desempenho. No entanto, é importante notar que ter mais parâmetros nem sempre garante melhores resultados; a qualidade dos dados de treinamento e os recursos computacionais disponíveis para o modelo também desempenham papéis significativos.
requisitos de sistema
Você precisará garantir que seu [Mac] tenha pelo menos as seguintes especificações:
- macOS 10.15 ou posterior (macOS 13 ou posterior recomendado)
- Pelo menos 8 GB de RAM (16 GB ou mais recomendados)
- 10 GB de espaço de armazenamento livre (o mínimo necessário para os modelos mais simples; modelos mais avançados com um número máximo de parâmetros requerem aproximadamente 700 GB).
- Processador multi-core [Intel] ou processador [Apple Silicon] (preferencialmente M2 ou superior)
Instalar Ollama
Ollama É uma ferramenta de código aberto que permite executar LLMs diretamente em sua máquina local. Veja como começar:
- Baixar Ollama: Visite o site Ollama Baixe a versão para macOS. Você também pode usar o [Homebrew] para instalá-la executando o seguinte comando:
brew install ollamaNo seu terminal.

- Instalar OllamaSe você baixou o instalador, clique duas vezes nele e siga o assistente de instalação. Se estiver usando o Homebrew, pule para o passo 4.

- O próximo passo para o instalador é simplesmente clicar no botão. تثبيتSerá solicitada a sua senha de administrador.
- Corra OllamaAbra uma janela de terminal e inicie o Ollama como um serviço usando o comando
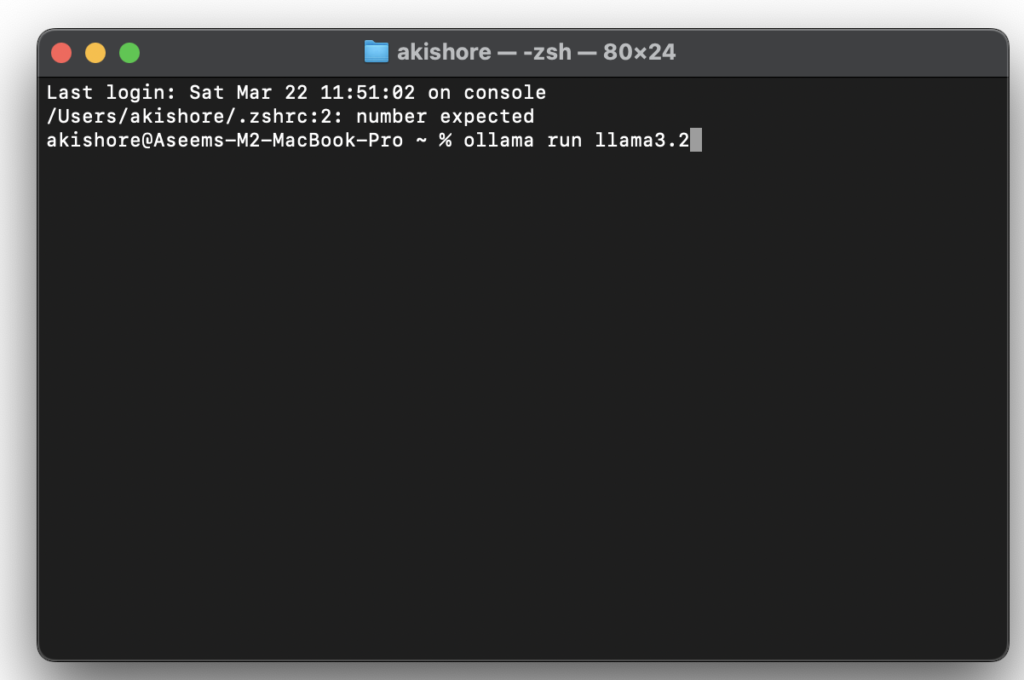
brew services start ollamaIsso tornará o Ollama disponível no endereço.http://localhost:11434/. - Baixe e execute o modelo.Use o comando
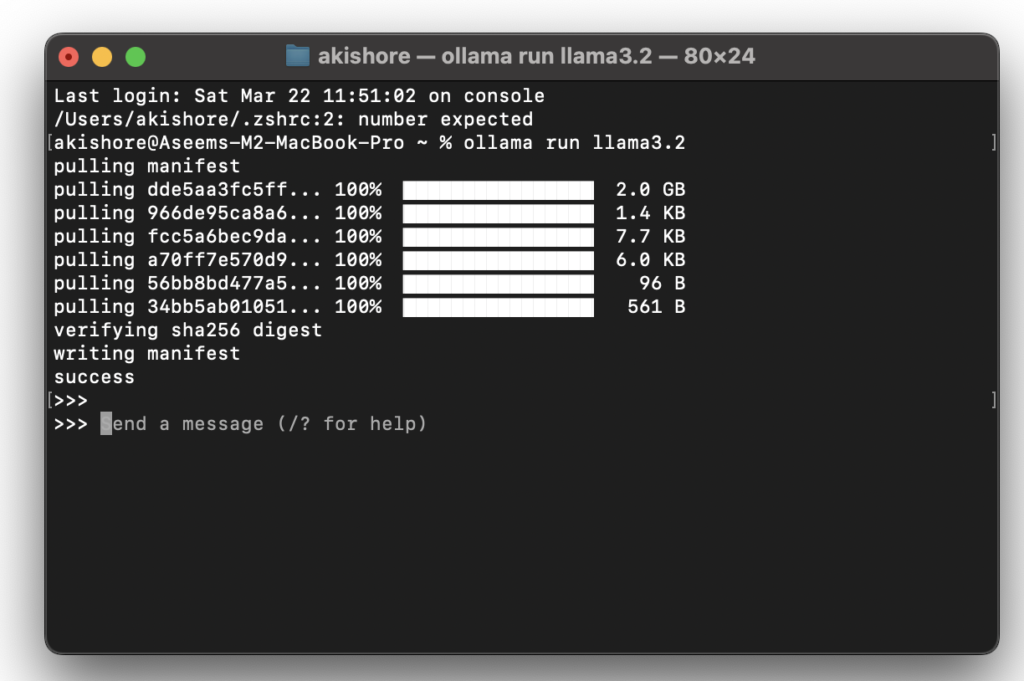
ollama pull <model-name>Para baixar um modelo, execute o comando.ollama run <model-name>Para executá-lo. Por exemplo, para executar um modelo. DeepSeek-R1, use o comandoollama pull deepseek-r1Seguido pelo pedidoollama run deepseek-r1. - Para baixar uma versão maior do modelo, basta adicionar dois pontos verticais seguidos do tamanho. Por exemplo, para baixar um modelo maior, digite: 14B DeepSeekVocê usará o comando ollama corre deepseek-r1:14bNo site da Ollama, você pode clicar em qualquer um dos formulários e todos os comandos diferentes para cada versão serão exibidos.
Você pode encontrar a lista completa de Modelos de lhama Aqui. Você também pode usar o segundo comando conforme descrito acima e, caso ainda não esteja instalado, ele primeiro baixará o formulário e depois o executará.
Agora que você vê as três setas em ângulo reto (>>>), você pode começar a digitar comandos no formulário.
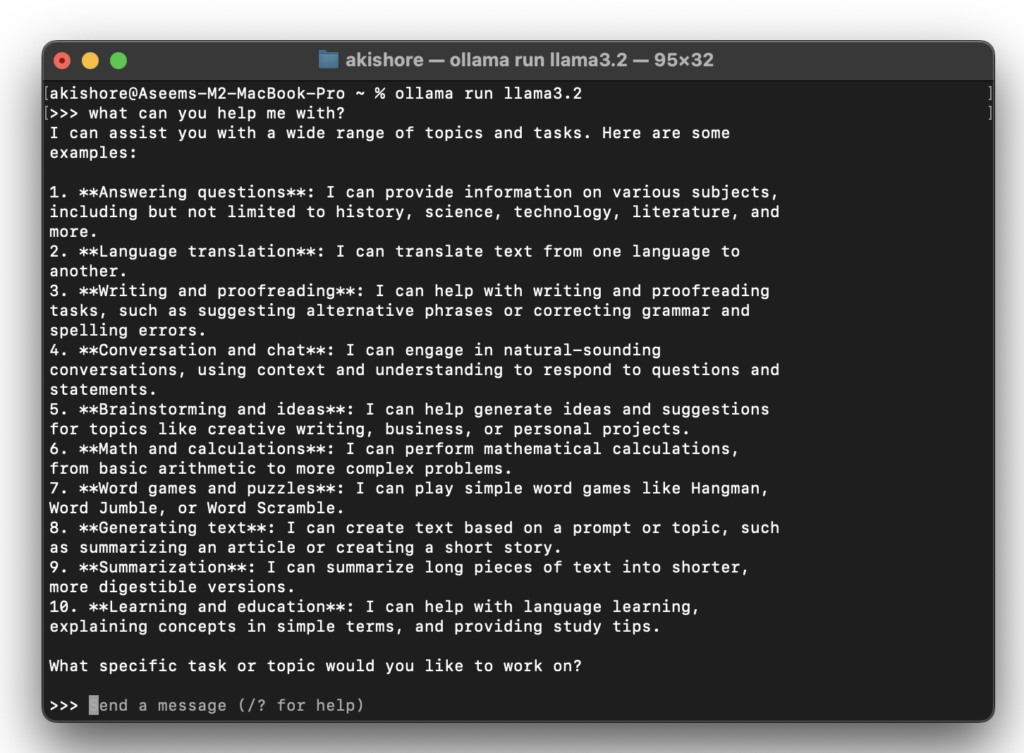
Pronto! Agora você pode interagir localmente com seu assistente virtual de IA sem se preocupar com custos, uso excessivo ou com outras pessoas lendo o que você escreve. Isso é ótimo se você tiver assuntos delicados ou pessoais que gostaria de discutir com um assistente virtual de IA, mas não quer que uma grande empresa de tecnologia leia seus pensamentos.
Utilizando ferramentas de interface gráfica de usuário com o Ollama
Embora o Ollama seja poderoso e eficiente para desenvolvedores, alguns usuários podem preferir uma interface gráfica de usuário (GUI) para interagir com LLMs. Aqui estão algumas ferramentas que podem fornecer uma interface gráfica de usuário para o Ollama:
-
-
- Interface gráfica do usuário OllamaEste é um aplicativo gratuito e de código aberto para usuários de macOS, desenvolvido em SwiftUI. Ele oferece uma interface elegante e é uma excelente opção para quem deseja acessar formulários LLM localmente sem usar o terminal.
- Interface do usuário OllamaUma interface de usuário web simples, baseada em HTML, que permite definir e interagir com formulários diretamente no seu navegador. Inclui também uma extensão para o Chrome para facilitar o acesso.
- Caixa de bate-papo IAEsta é a opção mais fácil para iniciantes, e explicarei como usá-la abaixo. Observe que você não precisa adquirir o serviço Chatbox AI, que é uma assinatura oferecida por eles para que você possa acessar todos os modelos do LLM sem precisar instalar o Ollama por conta própria.
-
Para usar a melhor interface de IA do Chatbox, acesse Página de download Obtenha a versão para o seu Mac.
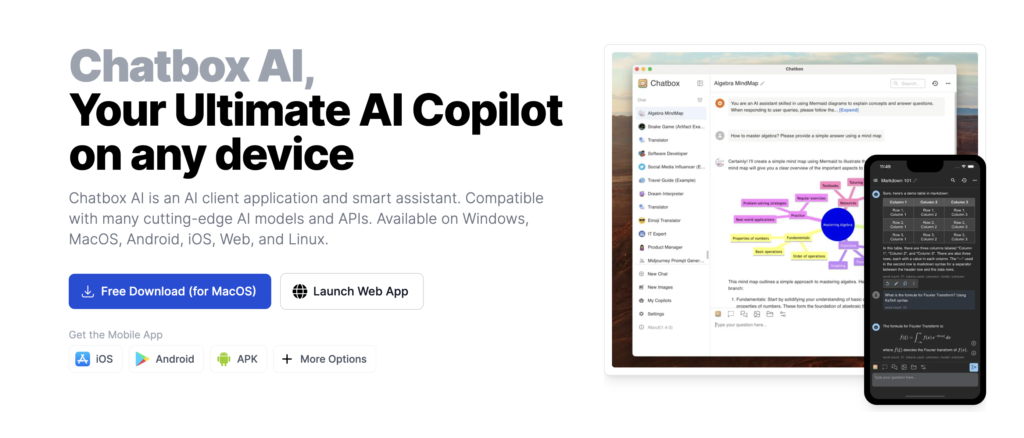
Em seguida, abra o instalador e execute o programa. Na primeira tela, uma janela pop-up aparecerá perguntando como usar o Chatbox AI.
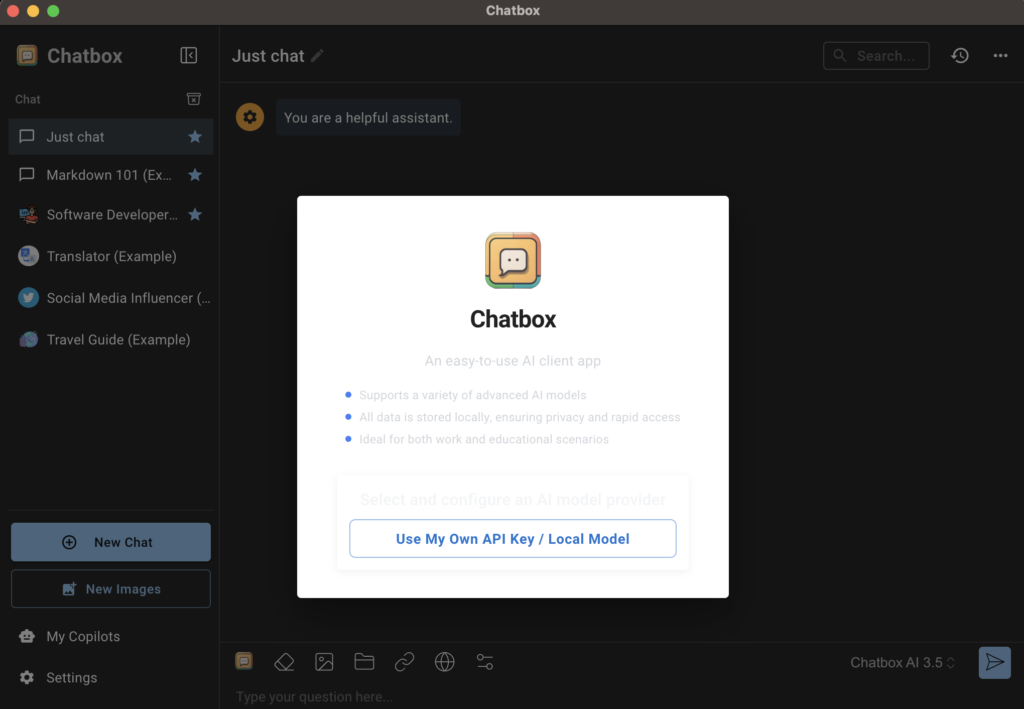
Você precisará clicar no botão. Usar minha própria chave de API / Modelo local.
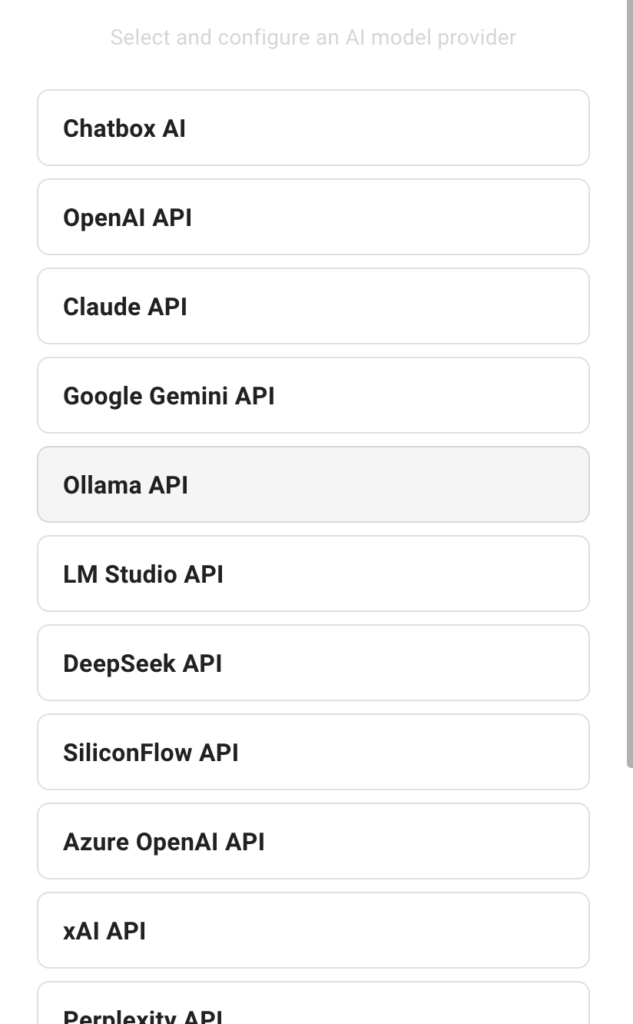
Em seguida, toque API Ollama Como fornecedor de modelos de inteligência artificial.
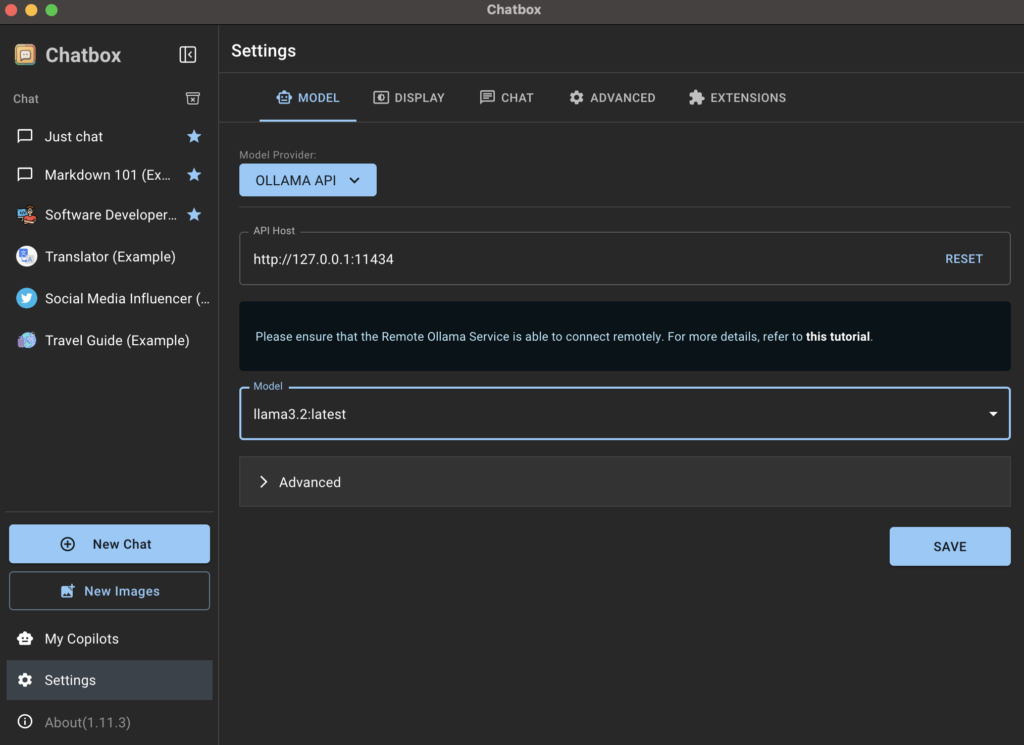
O Chatbox AI deve detectar automaticamente que o Ollama está em execução e definir o host da API para seu valor padrão, que é Endereço IP de retorno do loop e número da porta 11434Você não precisa alterar nada aqui. Dentro do formulário, você deverá ver os formulários que instalou anteriormente usando o Terminal. No meu caso, é o formulário lama 3.2.
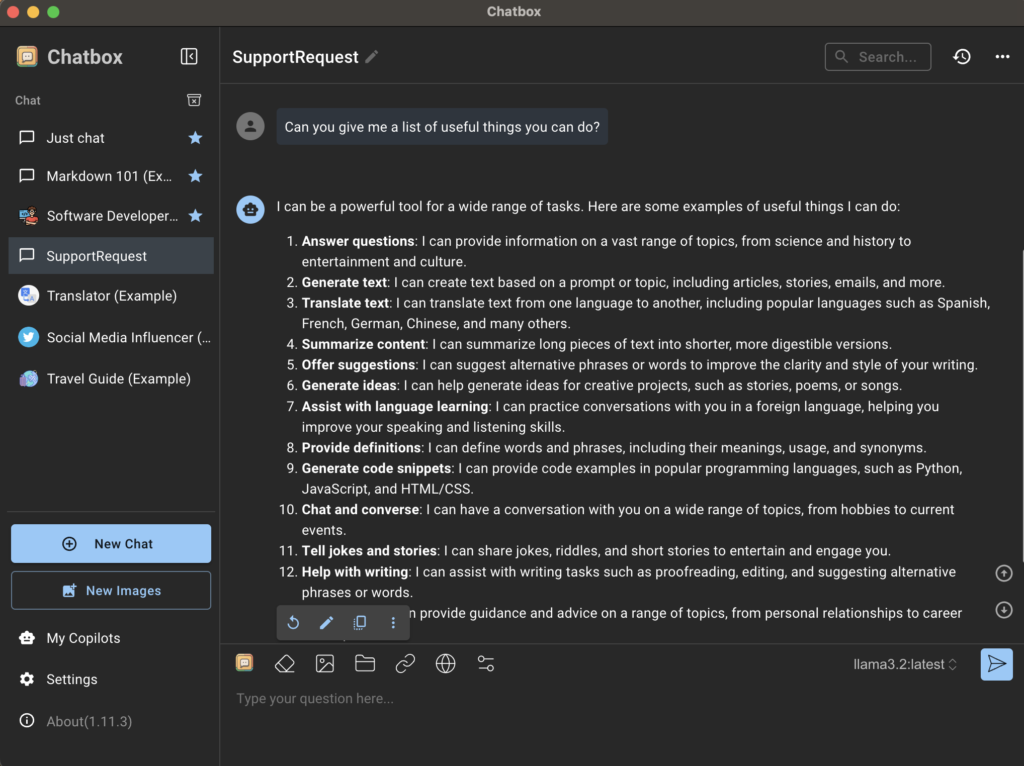
Ao retornar para a página inicial do aplicativo, clique em Apenas conversar أو Novo chat Certifique-se de selecionar o modelo correto no canto inferior direito. Você pode alterar o modelo a qualquer momento, mas recomendo criar um novo chat para cada modelo utilizado, para que possa visualizar facilmente as diferenças.
Ferramentas alternativas para executar modelos LLM localmente
Se você está procurando alternativas ao Ollama ou prefere uma experiência mais intuitiva desde o início, então Estúdio LM É outra excelente opção. Oferece uma interface amigável para explorar e usar vários modelos de IA, permitindo que você os baixe e execute facilmente. O LM Studio está disponível para Linux, Mac e Windows e oferece recursos como personalização de parâmetros do modelo e histórico de bate-papo. Atualmente é gratuito, por isso o recomendo em vez do serviço de assinatura Chatbox AI.
Conclusão
Executar grandes modelos de linguagem (LLMs) localmente no seu Mac será importante para quem busca maior controle sobre seus aplicativos de IA e prioriza a privacidade dos dados. Com ferramentas como o Ollama e as interfaces gráficas mencionadas anteriormente, que facilitam a integração de LLMs ao seu fluxo de trabalho, você pode desbloquear com segurança um novo potencial de produtividade e criatividade.
No entanto, iniciar uma implementação local do LLM requer alguma compreensão dos parâmetros e de como eles afetam o desempenho desses modelos em sua máquina específica. A melhor maneira de aprender isso é experimentar diferentes modelos para ver quais oferecem os melhores resultados. Depois de entender esse conceito, você poderá tomar decisões mais acertadas sobre quais modelos usar e como otimizar seu desempenho para atender às suas necessidades específicas.
Comentários estão fechados.