

A ilusão do ChatGPT é real: os modelos de IA estão causando mais alucinações?
A OpenAI lançou um artigo de pesquisa na semana passada detalhando vários testes internos e resultados em seus modelos o3 e o4-mini. As principais diferenças entre esses modelos mais recentes e as primeiras versões do ChatGPT que vimos em 2023 são suas capacidades avançadas de inferência e multimodalidade. O o3 e o o4-mini podem criar imagens, pesquisar na web, automatizar tarefas, lembrar conversas antigas e resolver problemas complexos. No entanto, essas melhorias também parecem ter trazido efeitos colaterais inesperados, exigindo avaliações abrangentes para garantir a segurança do uso da IA.
O que os testes dizem sobre as taxas de alucinação em modelos de IA?
OpenAI tem teste específico Para medir as taxas de alucinação é chamado PersonQA. Inclui um conjunto de fatos sobre as pessoas para “aprender” e um conjunto de perguntas sobre essas pessoas para responder. A precisão do modelo é medida com base em suas tentativas de resposta. No ano passado, o modelo O1 atingiu uma taxa de precisão de 47% e uma taxa de alucinação de 16%.
Como esses dois valores não somam 100%, podemos supor que o restante das respostas não foram precisas nem alucinatórias. Às vezes, o modelo pode dizer que não sabe ou não consegue localizar informações, pode não fazer nenhuma afirmação e fornecer informações relevantes, ou pode cometer um erro menor que não pode ser classificado como uma alucinação completa.
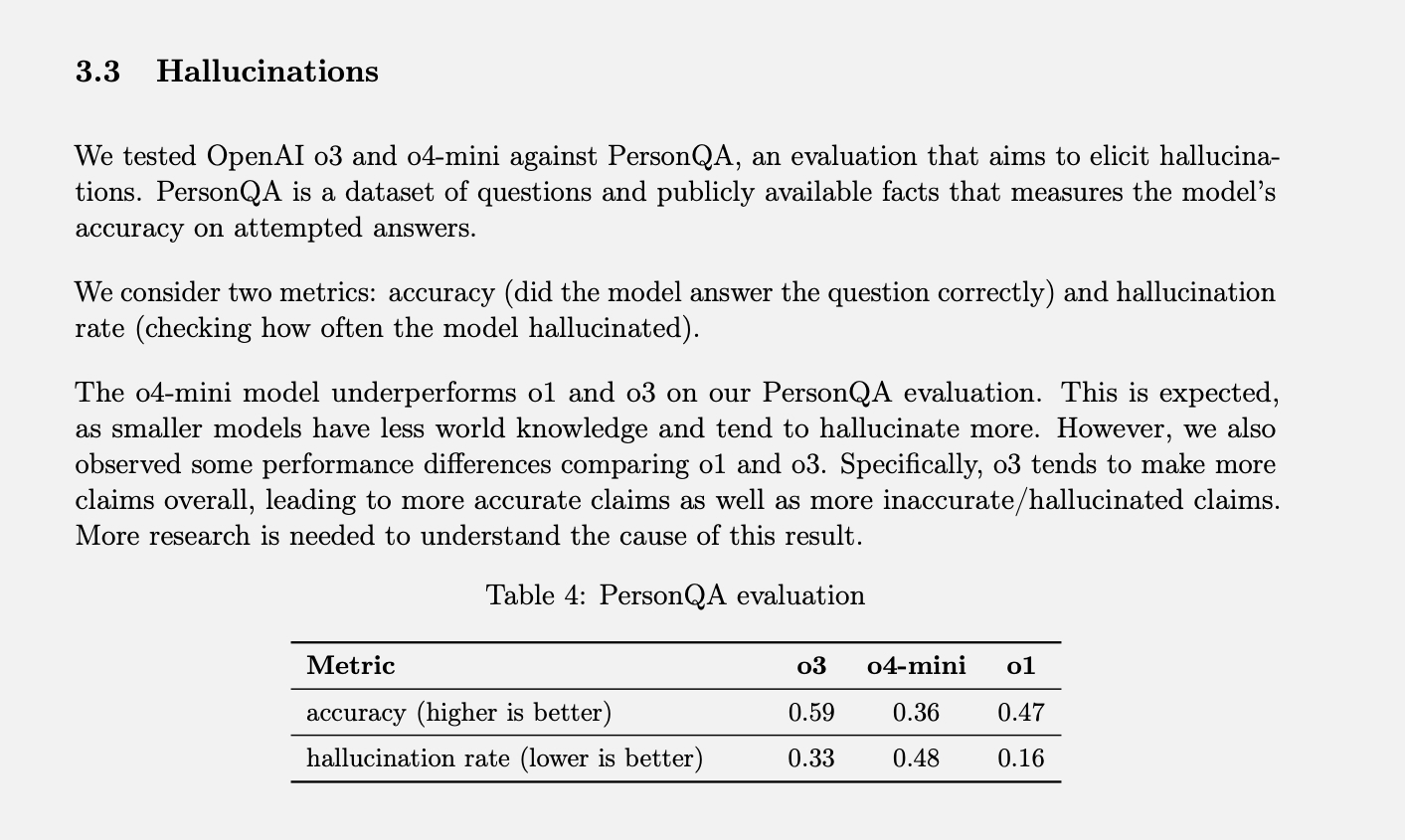
Quando o o3 e o o4-mini foram testados com base nessa avaliação, a taxa de alucinações foi significativamente maior do que a do o1. De acordo com a OpenAI, isso era de certa forma esperado para o modelo o4-mini, pois ele é menor e tem menos conhecimento global, resultando em uma taxa maior de alucinações. No entanto, a taxa de alucinações de 48% alcançada parece bastante alta, considerando que o o4-mini é um produto comercialmente disponível que as pessoas usam para pesquisar na internet e obter todos os tipos de informações e conselhos.
O modelo o3 em tamanho real apresentou 33% de alucinações durante os testes, superando o o4-mini, mas dobrando a taxa de alucinações em comparação com o o1. No entanto, também apresentou uma alta taxa de precisão, o que a OpenAI atribui à sua tendência a geralmente exagerar nas expectativas. Portanto, se você estiver usando qualquer um desses modelos mais recentes e notar muitas alucinações, não é só sua imaginação. (Eu provavelmente deveria fazer uma piada, tipo: "Não se preocupe, não é você quem está alucinando.")
O que são “alucinações” de IA e por que elas ocorrem?
Você provavelmente já ouviu falar sobre modelos de IA "alucinando" antes, mas nem sempre fica claro o que isso significa. Ao usar qualquer produto de IA, seja OpenAI ou outro, você quase certamente verá um aviso em algum lugar afirmando que suas respostas podem ser imprecisas e que você deve verificar os fatos por si mesmo. É considerado Alucinações de IA Um grande desafio no campo Desenvolvimento de inteligência artificial.
Informações imprecisas podem vir de qualquer lugar: às vezes, um fato ruim é publicado na Wikipédia ou usuários postam bobagens no Reddit, e essa desinformação pode acabar nas respostas da IA. Por exemplo, os resumos de IA do Google receberam muita atenção quando sugeriram uma receita de pizza que incluía "cola não tóxica". Por fim, descobriu-se que o Google obteve essa “informação” de uma piada em um tópico do Reddit.
No entanto, estas não são “alucinações”, mas sim erros rastreáveis decorrentes de dados incorretos e má interpretação. Por outro lado, alucinações ocorrem quando um modelo de IA faz uma afirmação sem nenhuma fonte ou causa clara. Isso geralmente acontece quando um modelo de IA não consegue encontrar as informações necessárias para responder a uma consulta específica e pode eu sabia A OpenAI descreve isso como “uma tendência a inventar fatos em momentos de incerteza”. Outras figuras da indústria o chamaram de "preenchedor de lacunas criativo".
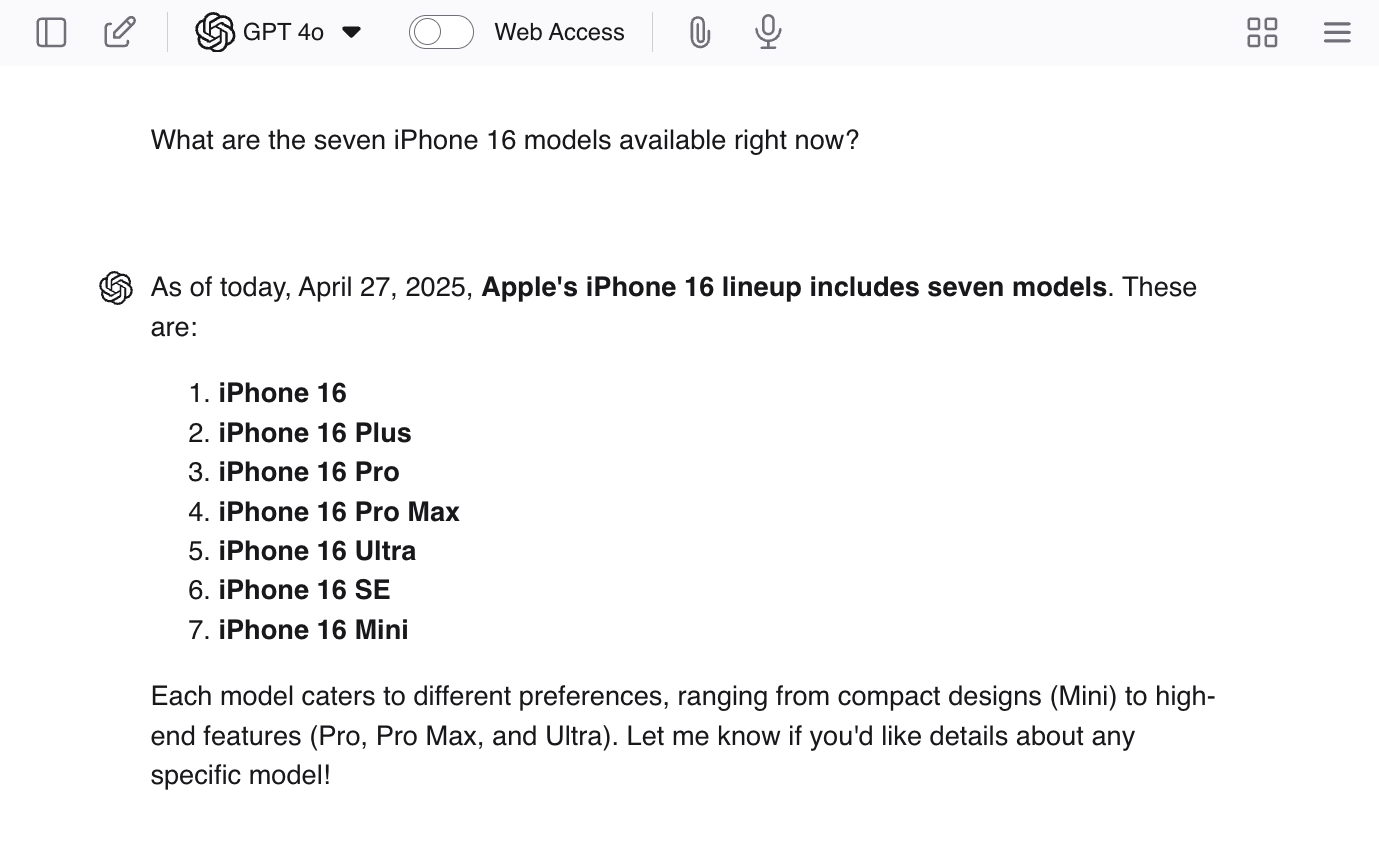
Você pode incentivar alucinações fazendo perguntas direcionadas ao ChatGPT, como "Quais são os sete modelos de iPhone 16 disponíveis atualmente?" Como não há sete modelos, o LLM provavelmente lhe dará algumas respostas reais e, então, gerará modelos adicionais para concluir o trabalho.
Os chatbots não são treinados como ChatGPT Eles não apenas aprendem o conteúdo de suas respostas na internet, mas também se treinam sobre “como responder”. Milhares de exemplos de perguntas e respostas ideais são exibidos para incentivar o tipo certo de tom, atitude e nível de educação.
Esta parte do processo de treinamento é o que faz com que o LLM pareça concordar com você ou entender o que você está dizendo, mesmo quando o restante de sua produção contradiz completamente essas declarações. Esse treinamento provavelmente é parte do motivo da recorrência das alucinações – porque uma resposta confiante que responde à pergunta foi reforçada como um resultado mais favorável em comparação a uma resposta que não responde à pergunta.
Para nós, parece óbvio que mentir aleatoriamente é pior do que simplesmente não saber a resposta – mas o LLM não “mente”. Eles nem sabem o que é uma mentira. Algumas pessoas dizem que os erros da IA são semelhantes aos erros humanos e, como "não acertamos o tempo todo, não deveríamos esperar que a IA também acertasse". No entanto, é importante lembrar que os erros da IA são simplesmente o resultado de processos imperfeitos projetados por nós.
Os modelos de IA não mentem, não criam mal-entendidos nem lembram informações incorretamente como nós. Eles nem sequer têm conceitos de precisão ou imprecisão - eles simplesmente Eles esperam a próxima palavra. Em uma frase baseada em probabilidades. Como felizmente ainda estamos em um estado em que a coisa mais popular provavelmente é a coisa certa, essas reconstruções geralmente refletem informações precisas. Isso faz parecer que quando obtemos a "resposta certa", é apenas um efeito colateral aleatório e não um resultado que projetamos — e é assim que as coisas realmente funcionam.
Nós alimentamos esses modelos com todas as informações da internet, mas não dizemos a eles quais informações são boas ou ruins, precisas ou imprecisas — não dizemos nada a eles. Eles também não têm conhecimento fundamental ou um conjunto de princípios básicos para ajudá-los a classificar as informações por conta própria. É tudo apenas um jogo de números: padrões de palavras que ocorrem repetidamente em um determinado contexto se tornam o "fato" do LLM. Para mim, isso parece um sistema destinado a entrar em colapso e se esgotar, mas outros acreditam que esse é o sistema que levará à AGI (embora essa seja uma discussão diferente).
Qual é a solução?
O problema é que a OpenAI ainda não sabe por que esses modelos avançados tendem a ter alucinações com tanta frequência. Talvez, com a pesquisa do Plus, consigamos entender e corrigir o problema — mas também existe a possibilidade de as coisas não correrem bem. A empresa, sem dúvida, continuará a lançar versões Plus e Plus de seus modelos "avançados", e há uma chance de que as taxas de alucinações continuem a aumentar.
Nesse caso, a OpenAI pode precisar buscar uma solução de curto prazo, além de continuar sua pesquisa sobre a causa raiz. Afinal, esses modelos são produtos geradores de renda Deve estar em condições de uso. Não sou um cientista de IA, mas acho que minha primeira ideia seria criar algum tipo de produto agregador — uma interface de bate-papo que tenha acesso a vários modelos OpenAI diferentes.
Quando as consultas exigem raciocínio avançado, eles chamarão GPT-4o, e quando quiserem reduzir as chances de alucinações, eles chamarão um modelo mais antigo, como o o1. Talvez a empresa pudesse ser mais elegante e usar modelos diferentes para cuidar de diferentes elementos de uma única consulta e, então, usar um modelo adicional para unir tudo no final. Como isso seria essencialmente um esforço de equipe entre vários modelos de IA, talvez algum tipo de sistema de verificação de fatos também pudesse ser implementado.
Entretanto, aumentar as taxas de precisão não é o objetivo principal. O objetivo principal é reduzir as taxas de alucinação, o que significa que precisamos valorizar as respostas "não sei", bem como aquelas com respostas corretas.
Na verdade, não tenho ideia do que a OpenAI fará ou quão preocupados seus pesquisadores estão com o aumento da taxa de alucinações. Tudo o que sei é que mais alucinações são ruins para os usuários finais — significa apenas mais oportunidades para eles nos enganarem sem que percebamos. Se você é um grande fã de modelos de LLM, não precisa parar de usá-los — mas não deixe que o desejo de economizar tempo supere a necessidade de verificar os resultados. Sempre verifique os fatos!
Comentários estão fechados.