

Por que a maioria dos modelos de risco de segurança cibernética falham antes de começar
A necessidade de pensamento quantitativo sobre os riscos da segurança cibernética
Líderes de segurança cibernética enfrentam perguntas impossíveis. “Qual é a probabilidade de uma violação de segurança este ano?” e "Quanto custará?" e “Quanto devemos gastar para impedir isso?”
Entretanto, a maioria dos modelos de risco usados hoje ainda se baseiam em suposições, instintos e mapas de risco codificados por cores, não em dados.
Na verdade, eu encontrei Estudo Global Digital Trust Insights da PwC 2025 Apenas 15% das organizações usam modelagem quantitativa de risco em extensão significativa.
Este artigo explora por que os modelos tradicionais de risco de segurança cibernética falham e como a aplicação de algumas ferramentas estatísticas leves, como a modelagem probabilística, oferece um caminho melhor a seguir.

Duas principais escolas de pensamento em modelagem de risco cibernético
Os modelos de risco cibernético são: Estruturas ou métodos sistemáticos usados para analisar, avaliar e mensurar ameaças à segurança cibernética e seu impacto potencial em sistemas de informação, dados ou negócios.
Profissionais de segurança da informação usam principalmente dois métodos diferentes de modelagem de risco durante o processo de avaliação de risco: qualitativo e quantitativo. É considerado Modelagem quantitativa de riscos cibernéticos Uma técnica avançada que requer conhecimento especializado.
Modelos qualitativos para avaliação de risco
Imagine duas equipes avaliando o mesmo risco. Atribui-se ao risco uma pontuação de 4/5 para probabilidade e 5/5 para impacto. O outro time dá a ela 3/5 e 4/5. Ambas as equipes o localizam em uma matriz. Mas nenhum dos dois consegue responder à pergunta do CFO: "Qual é a probabilidade de isso realmente acontecer e quanto isso vai nos custar?"
A abordagem qualitativa baseia-se na avaliação subjetiva de riscos e provém principalmente da intuição do avaliador. Uma abordagem qualitativa geralmente resulta na classificação da probabilidade e do impacto dos riscos em uma escala ordinal, como 1 a 5.
Em seguida, os riscos são localizados na matriz de riscos para entender onde eles se encaixam nessa escala ordinal.
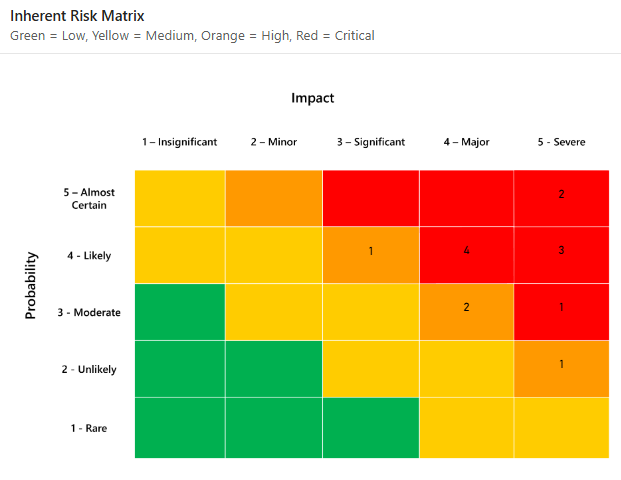
As duas escalas ordinais são frequentemente multiplicadas para ajudar a priorizar os riscos mais significativos com base na probabilidade e no impacto. À primeira vista, isso parece razoável, já que a definição comumente usada de risco em segurança da informação é:
[texto{Risco} = texto{Probabilidade} vezes texto{Impacto}]
Entretanto, do ponto de vista estatístico, a modelagem qualitativa de risco envolve alguns riscos muito significativos.
O primeiro desses riscos é o uso de escalas ordinais. Embora atribuir números à escala ordinal dê a aparência de suporte matemático ao modelo, isso é apenas uma ilusão.
Escalas ordinais são simplesmente rótulos – não há distância definida entre elas. A distância entre um risco que tem um impacto de “2” e um impacto de “3” não é quantificável. Alterar os rótulos na escala ordinal para “A”, “B”, “C”, “D” e “E” não faz diferença.
Isso, por sua vez, significa que nossa formulação de risco é falha quando usamos modelagem qualitativa. É impossível calcular a probabilidade de “B” multiplicada pelo efeito de “C”.
Outra grande armadilha é a incerteza da modelagem. Quando modelamos riscos cibernéticos, estamos modelando eventos futuros incertos. Na verdade, há uma série de resultados que podem ocorrer.
Destilar o risco cibernético em estimativas de ponto único (como "20/25" ou "Alto") não captura a importante distinção entre "a perda anual mais provável é de US$ 1 milhão" e "há 5% de chance de uma perda de US$ 10 milhões ou mais".
Modelagem Quantitativa de Risco: Análise Avançada
Imagine uma equipe realizando uma avaliação de risco. Eles estimam uma gama de resultados, de US$ 100 a US$ 10 milhões. Ao executar uma simulação de Monte Carlo, eles extraem uma chance de 10% de exceder US$ 480 milhão em perdas anuais e uma perda esperada de US$ XNUMX. Agora, quando o CFO pergunta, “Qual é a probabilidade de isso acontecer e quanto custará?”A equipe pode responder com dados, não apenas com intuição.
Esta abordagem desloca a conversa de classificações de risco vagas para Possibilidades e potencial impacto financeiro, uma linguagem que os executivos entendem.
Se você tem formação em estatística, um conceito em particular deve se destacar aqui:
Probabilidade.
A modelagem de risco de segurança cibernética é, em sua essência, uma tentativa de quantificar a probabilidade de certos eventos ocorrerem e o impacto caso ocorram. Isso abre as portas para uma variedade de ferramentas estatísticas, como a simulação de Monte Carlo, que pode modelar a incerteza de forma muito mais eficaz do que as medidas ordinais.
A modelagem quantitativa de risco usa modelos estatísticos para atribuir valores monetários às perdas e modelar a probabilidade desses eventos de perda ocorrerem, capturando a incerteza futura.
Embora a análise qualitativa possa, às vezes, aproximar-se do resultado mais provável, ela não consegue capturar toda a gama de incertezas, como eventos raros, mas impactantes, conhecidos como “risco de cauda longa”.
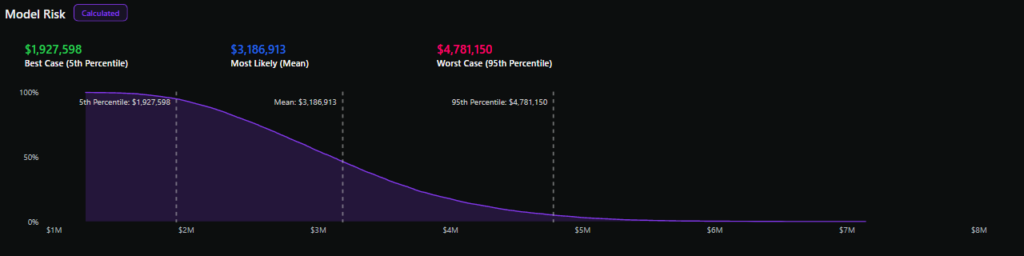
A curva de excesso de perdas representa a probabilidade de exceder um determinado valor de perda anual no eixo y, e diferentes valores de perdas no eixo x, resultando em uma linha inclinada para baixo.
Extrair diferentes porcentagens da curva de excesso de perdas, como o 90º percentil, a mediana e o XNUMXº percentil, pode fornecer uma ideia das perdas anuais potenciais para um risco com XNUMX% de confiança.
Embora uma estimativa de ponto único da análise qualitativa possa aproximar os riscos mais prováveis (dependendo da precisão do julgamento dos avaliadores), a análise quantitativa captura a incerteza nos resultados, mesmo aqueles que são raros, mas ainda possíveis (conhecidos como “risco de cauda longa”).
Olhando além do risco cibernético: aprimorando os modelos de risco em segurança cibernética
Para melhorar nossos modelos de risco em segurança da informação, tudo o que precisamos fazer é olhar para fora, especificamente para as tecnologias usadas em outros campos. Os modelos de risco evoluíram significativamente em diversas aplicações, como finanças, seguros, segurança da aviação e gerenciamento da cadeia de suprimentos. Essas áreas fornecem insights valiosos que podem ser aplicados à segurança cibernética.
As equipes financeiras usam modelos para gerenciar o risco do portfólio de investimentos usando estatísticas bayesianas semelhantes. Enquanto as equipes de seguros modelam riscos usando modelos atuariais sofisticados. A indústria da aviação modela o risco de falha de sistemas usando modelos de probabilidade. As equipes de gerenciamento da cadeia de suprimentos modelam riscos usando simulação probabilística. Essas metodologias fornecem uma base sólida para o desenvolvimento de modelos eficazes de risco cibernético.
As ferramentas já existem. Os fundamentos matemáticos são bem compreendidos. Outras indústrias abriram caminho. Agora é hora de a segurança cibernética adotar modelos de risco quantitativos para tomar decisões melhores e mais informadas, levando a melhores estratégias de segurança cibernética e à redução de perdas potenciais. A adoção desses modelos quantitativos representa um passo crucial para uma gestão de risco cibernético mais eficaz.
الخلاصة الرئيسية
| Alamy Annihil | Análise quantitativa |
| Escalas ordinais (1-5) | Modelagem probabilística |
| intuição pessoal | precisão estatística |
| Pontos de avaliação individuais | Distribuições de risco |
| Mapas de calor e códigos de cores | Curvas de excedência de perdas |
| Ignora eventos raros, mas graves | Captura risco de cauda longa |
Comentários estão fechados.