

Explicação: Como a Regularização L1 seleciona recursos automaticamente?
Entenda o processo de seleção automática de recursos realizado pela Regularização L1 (LASSO).
A seleção de recursos é o processo de selecionar um subconjunto ideal de recursos de um determinado conjunto de recursos; O subconjunto ideal é aquele que maximiza o desempenho do modelo na tarefa dada.
A identificação de recursos pode ser um processo manual ou bastante explícito quando feito usando métodos de filtro ou métodos wrapper. Nesses métodos, os recursos são adicionados ou removidos iterativamente com base no valor de uma métrica fixa, que determina a importância do recurso na realização de uma previsão. As métricas podem ser ganho de informação, variância ou estatística qui-quadrado, e o algoritmo tomará a decisão de aceitar/rejeitar o recurso levando em consideração um limite fixo na métrica. Vale ressaltar que esses métodos não fazem parte da fase de treinamento do modelo e são executados antes dela.
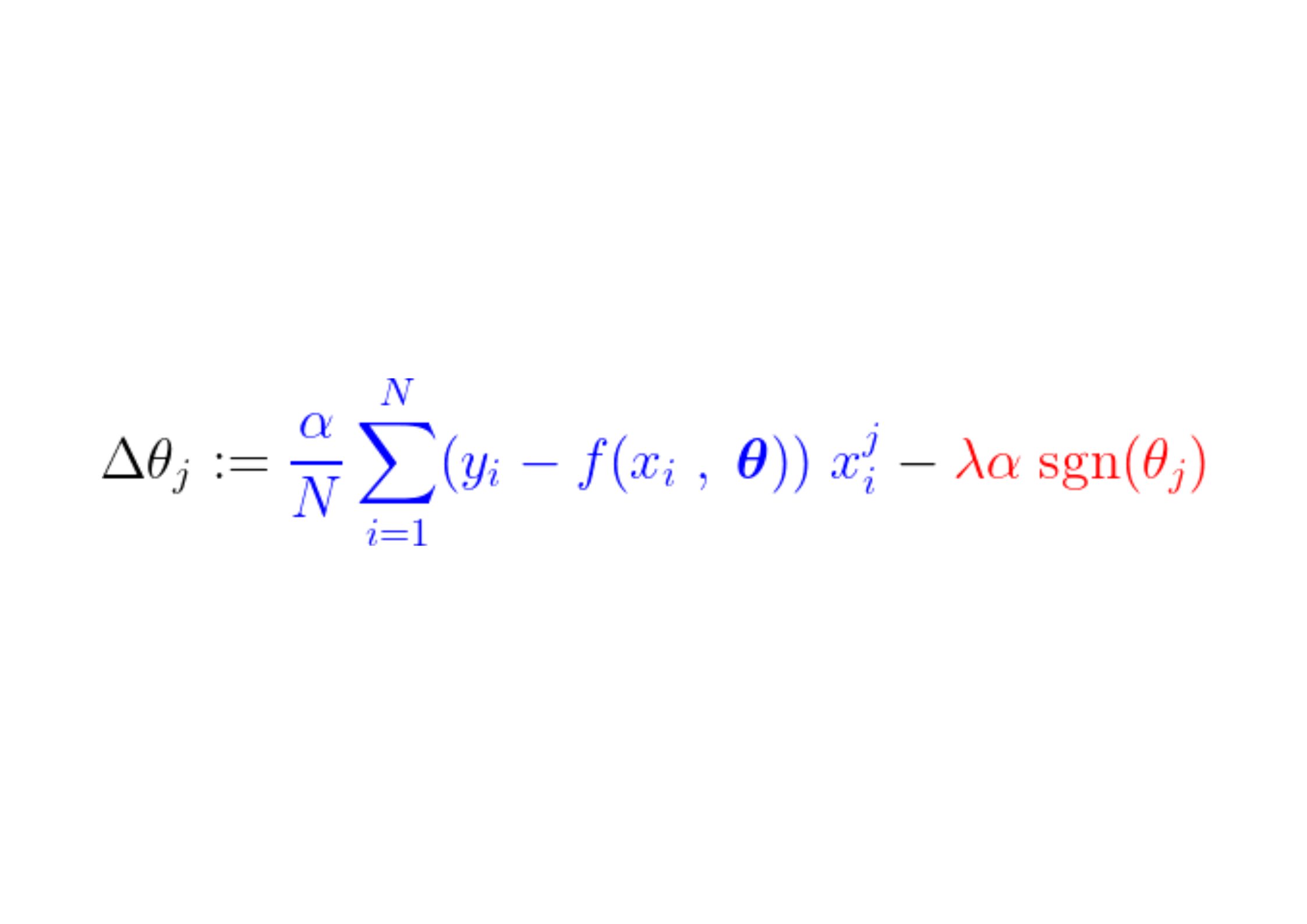
Levante-se Métodos incorporados Selecionando recursos implicitamente, sem usar nenhum critério de seleção predefinido, e extraindo-os dos próprios dados de treinamento. Este processo de identificação de recursos essenciais faz parte da fase de treinamento do modelo. O modelo aprende a identificar recursos e fazer previsões relevantes ao mesmo tempo. Nas seções subsequentes, descreveremos o papel da regularização nesse processo essencial de seleção de recursos, com foco na regularização L1 e seu papel na melhoria de modelos de aprendizado de máquina.
Normalização e Complexidade do Modelo: Estratégias Avançadas para Melhorar o Desempenho
Regularização é o processo de penalizar a complexidade do modelo para evitar overfitting e obter generalização para a tarefa.
Aqui, a complexidade do modelo é análoga à sua capacidade de se adaptar aos padrões nos dados de treinamento. Assumindo um modelo polinomial simples em 'x'até certo ponto'dQuanto maior a pontuaçãodPara polinômios, o modelo tem maior flexibilidade para capturar padrões nos dados observados. Essa maior flexibilidade pode levar o modelo a memorizar os dados de treinamento em vez de aprender os padrões verdadeiros, o que reduz sua capacidade de generalização para novos dados.
Sobreajuste e subajuste
Ao tentar ajustar um modelo polinomial com grau d = 2 Em um conjunto de amostras de treinamento extraídas de um polinômio de terceira ordem com algum ruído, o modelo não será capaz de capturar adequadamente a distribuição de amostragem. O modelo simplesmente não tem Flexibilidade أو complexidade Necessário para modelar dados gerados por polinômios de grau 3 (ou superior). Diz-se que este modelo é subajustado Sobre dados de treinamento. A subcarga indica que o modelo é muito simples e não consegue capturar os padrões subjacentes nos dados.
Trabalhando com o mesmo exemplo, agora assumimos que temos um modelo com um grau de d = 6. Agora, com o aumento da complexidade, deve ser fácil para o modelo estimar o polinômio cúbico original que foi usado para gerar os dados (por exemplo, definir os coeficientes de todos os termos com expoente > 3 como 0). Se o processo de treinamento não for concluído a tempo, o modelo continuará a usar sua flexibilidade adicional para reduzir ainda mais o erro e começar a capturar amostras ruidosas também. Isso reduzirá bastante o erro de treinamento, mas o modelo agora está sobreajustes Sobre dados de treinamento. O ruído mudará em cenários do mundo real (ou na fase de testes) e qualquer conhecimento baseado em previsão será interrompido, resultando em alto erro de teste. Sobrecarga significa que o modelo é muito complexo e aprende ruído em vez do sinal real.
Como determinar a complexidade ótima do modelo?
Em cenários práticos, muitas vezes temos compreensão limitada ou nenhuma do processo de geração de dados ou da verdadeira distribuição de dados. Encontrar o modelo ideal com a complexidade apropriada, para que não haja subajuste ou superajuste, é um desafio significativo. Isso requer o uso de métodos eficazes para avaliar o desempenho dos modelos e determinar a complexidade apropriada que alcance o melhor equilíbrio entre precisão e generalidade. Ao usar métricas e técnicas de avaliação apropriadas, como validação cruzada, os profissionais podem identificar o modelo que tem melhor desempenho em dados não vistos, evitando assim problemas de ajuste excessivo ou insuficiente.
Uma técnica possível é começar com um modelo suficientemente robusto e então reduzir sua complexidade por meio da seleção de recursos. Quanto menos recursos, menos complexo será o modelo.
Como discutimos na seção anterior, a seleção de recursos pode ser explícita (métodos de filtragem, métodos de convolução) ou implícita. Recursos redundantes que não são muito importantes na determinação do valor da variável de destino devem ser removidos para evitar que o modelo aprenda padrões não correlacionados neles. A regularização também executa uma tarefa semelhante. Então, como a regularização e a seleção de recursos se relacionam para atingir um objetivo comum de complexidade ideal do modelo? Reduzir a complexidade em modelos de aprendizado de máquina é crucial para melhorar o desempenho e evitar overfitting, que é o foco da regularização e da seleção de recursos.
Regularização L1 como determinante de característica
Continuando com nosso modelo polinomial, o representamos como uma função f, com entradas x, e transações θ e grau d،
![]()
Para um modelo polinomial, cada potência da entrada pode ser considerada XI Como vantagem, formar um vetor da seguinte forma:
![]()
Também definimos uma função objetivo, cuja minimização leva aos parâmetros ótimos. θ * O termo inclui: regularização (Regulamentação) que penaliza a complexidade do modelo.
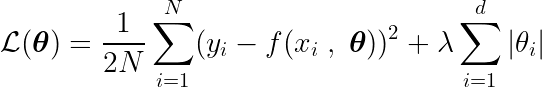
Para encontrar o mínimo desta função, precisamos analisar todos os pontos críticos, ou seja, os pontos onde a derivada é zero ou indefinida.
A derivada parcial pode ser escrita em relação a um dos parâmetros, θj, Do seguinte modo:
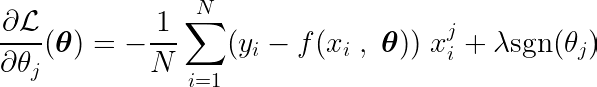
onde a função é definida sinal Do seguinte modo:
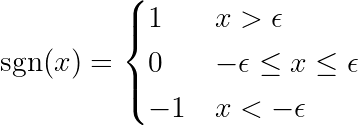
NotaA derivada de uma função absoluta é diferente da função de sinal (sgn) definida acima. A derivada original é indefinida em x = 0. Estendemos a definição para remover o ponto de inflexão em x = 0 e tornar a função diferenciável em todo o seu intervalo. Além disso, as estruturas de aprendizado de máquina (ML) usam essas funções estendidas quando os cálculos subjacentes envolvem a função absoluta. Olha só isso! الرابط No fórum PyTorch.
Calculando a derivada parcial da função objetivo em relação a um único coeficiente θj, e igualando-o a zero, podemos construir uma equação que liga o valor ótimo de θj Com previsões, gols e recursos.
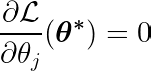
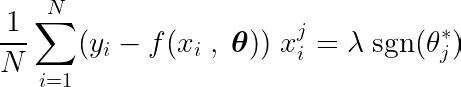
Vamos examinar a equação acima. Supondo que as entradas e metas foram centralizadas em torno da média (ou seja, os dados foram padronizados na etapa de pré-processamento), o termo do lado esquerdo (LHS) representa efetivamente variação Entre o recurso número j e a diferença entre os valores esperados e alvo.
A covariância estatística entre duas variáveis determina a quantidade de influência que uma variável tem sobre o valor da segunda variável (e vice-versa).
A função de sinal do lado direito força a variação do lado esquerdo a assumir apenas três valores (já que a função de sinal retorna apenas -1, 0 e 1). Se o recurso j Desnecessário e não afeta as previsões, a variância será próxima de zero, tornando o coeficiente correspondente θj* Zero. Isso faz com que o recurso seja removido do modelo. Esse processo ajuda a reduzir a complexidade e melhorar o desempenho do modelo.
Imagine a função do sinal como um sulco esculpido pela água. Você pode caminhar até a ravina (ou seja, o leito do rio), mas para sair dela, você encontrará enormes barreiras ou corredeiras íngremes. A regularização L1 cria um efeito de “limiar” semelhante ao gradiente da função de perda. O gradiente deve ser forte o suficiente para quebrar as barreiras ou se tornar zero, eventualmente tornando o valor do coeficiente zero.
Para fornecer um exemplo mais realista, considere um conjunto de dados contendo amostras derivadas de uma linha reta (parametrizada em dois fatores) com algum ruído adicionado. O modelo ideal não deve ter mais de dois parâmetros, caso contrário, ele se ajustará excessivamente ao ruído nos dados (com a liberdade/poder adicional do polinômio). Alterar os coeficientes de potência mais altos em um modelo polinomial não afeta a diferença entre os alvos e as previsões do modelo e, portanto, reduz sua variância com o recurso.
Durante o processo de treinamento, um passo fixo é adicionado/subtraído do gradiente da função de perda. Se o gradiente da função de perda (MSE – erro quadrático médio) for menor que o passo constante, o coeficiente eventualmente atingirá um valor de 0. Observe a equação abaixo, que descreve como os coeficientes são atualizados usando a descida do gradiente:

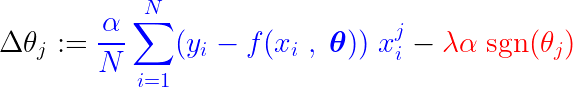
Se a parte azul acima for menor que La, que é um número muito pequeno em si, então Δθj É quase um passo constante. La. O sinal para esta etapa (parte vermelha) depende de: sgn(θj), cuja saída depende de θj. Se o valor for θj Positivo, ou seja, maior que ε, Então sgn(θj) é igual a 1, tornando assim Δθj Aproximadamente igual a -La, empurrando-o em direção a zero.
Para suprimir o passo constante (parte vermelha) que torna o coeficiente zero, o gradiente da função de perda (parte azul) deve ser maior que o tamanho do passo. Para obter um gradiente maior para a função de perda, o valor do recurso deve afetar significativamente a saída do modelo.
É assim que o recurso, ou mais precisamente, seu parâmetro correspondente, cujo valor não está relacionado à saída do modelo, é zerado pela regularização L1 durante o treinamento.
Leituras adicionais e conclusão
- Para obter mais informações sobre este tópico, postei uma pergunta no Reddit r/MachineLearning eAcompanhamento Ele contém diferentes interpretações que você pode querer ler.
- Madiyar Aitbayev também tem blog interessante Abrange a mesma questão, mas com uma explicação de engenharia.
- Blog Brian King explica a organização de uma perspectiva probabilística.
- Isto النقاش No site CrossValidated, ele explica por que o critério L1 incentiva modelos esparsos. Blog Um artigo detalhado de Mukul Ranjan explica por que a norma L1 incentiva as transações a se tornarem zero e a norma L2 não.
“A regularização L1 seleciona recursos” é uma afirmação simples com a qual a maioria dos alunos de ML concorda, sem entrar em detalhes sobre como ela funciona internamente. Este blog é uma tentativa de apresentar meu entendimento e modelo mental aos leitores para responder à pergunta de forma intuitiva. Para sugestões e dúvidas, você pode encontrar meu e-mail em Meu site. Continue aprendendo e tenha um dia maravilhoso!
Comentários estão fechados.