

Meta ensina aos modelos de IA a arte de distinguir entre comandos importantes e outros.
Modelos de raciocínio como OpenAI o1 e DeepSeek-R1 têm problemas com excesso de raciocínio. Se você fizer uma pergunta simples como "Quanto é 1+1?", ela pensará por vários segundos antes de responder.

O ideal é que os modelos de IA, assim como os humanos, sejam capazes de determinar quando fornecer uma resposta direta e quando alocar tempo e recursos adicionais para pensar antes de responder. E isso acontece nova tecnologia Apresentado por pesquisadores em Meta IA وUniversidade de Illinois em Chicago Treinando modelos para alocar orçamentos de inferência com base na dificuldade da consulta. Isso resulta em respostas mais rápidas, custos mais baixos e melhor alocação de recursos de computação.
raciocínio custoso
Grandes modelos de linguagem (LLMs) podem melhorar seu desempenho em tarefas de raciocínio quando produzem cadeias de pensamento mais longas, frequentemente conhecidas como “cadeias de pensamento” (CoT). O sucesso da técnica da cadeia de ideias levou a um conjunto de técnicas de escalonamento de tempo de inferência que forçam o modelo a "pensar" mais profundamente sobre o problema, gerar e revisar múltiplas respostas e escolher a melhor.
A votação majoritária (VM) é um dos principais métodos usados em modelos de raciocínio, onde múltiplas respostas são geradas e a resposta mais frequente é escolhida. O problema com essa abordagem é que o modelo adota um comportamento uniforme, tratando cada entrada como um problema de raciocínio difícil e consumindo recursos desnecessários para gerar múltiplas respostas.
Raciocínio inteligente
O novo artigo de pesquisa propõe uma série de técnicas de treinamento que tornam os modelos de raciocínio mais eficientes na resposta. O primeiro passo é a “votação sequencial” (VE), onde o modelo aborta o processo de raciocínio quando uma determinada resposta aparece um certo número de vezes. Por exemplo, o formulário é solicitado a gerar no máximo oito respostas e escolher a resposta que aparece pelo menos três vezes. Se o modelo receber a consulta simples acima, as três primeiras respostas provavelmente serão semelhantes, o que levará à parada antecipada, economizando tempo e recursos de computação.
Seus experimentos mostram que o SV supera o MV clássico em problemas de competição matemática quando gera o mesmo número de respostas. No entanto, o SV requer instruções adicionais e geração de código, o que o coloca no mesmo nível do MV em termos de relação código-precisão.
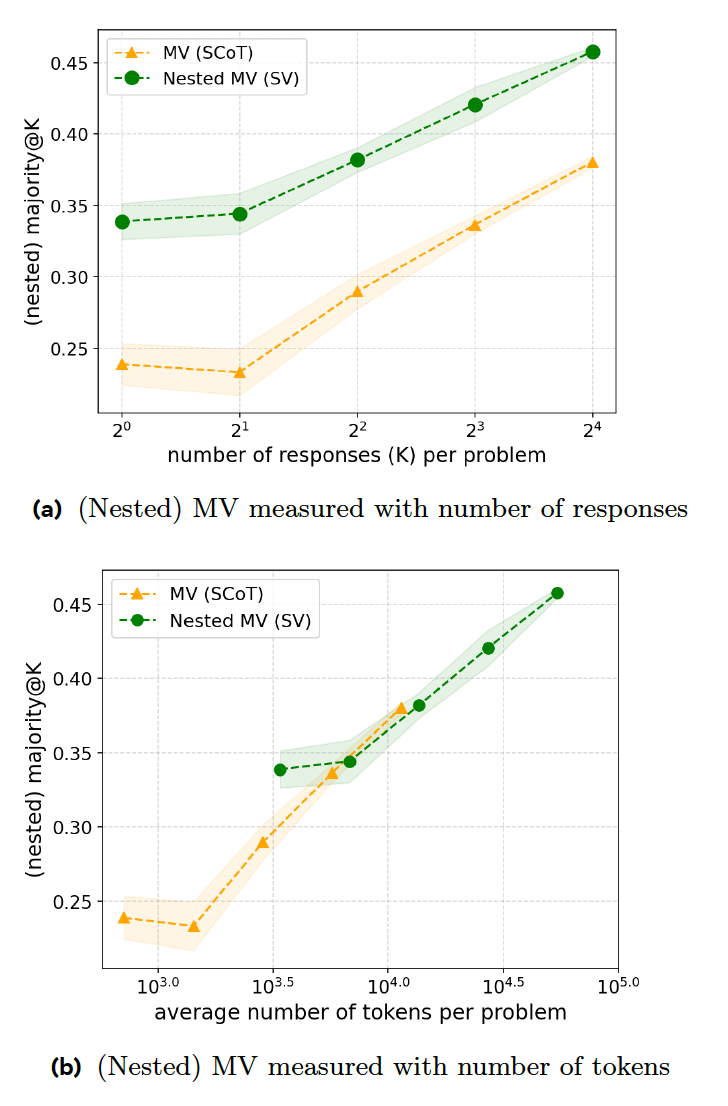
A segunda técnica, Votação Sequencial Adaptativa (ASV), melhora a SV ao exigir que o modelo examine o problema e gere múltiplas respostas somente quando o problema for difícil. Para problemas simples (como uma afirmação 1+1), o modelo simplesmente gera uma única resposta sem passar pelo processo de votação. Isso torna o modelo mais eficiente no tratamento de problemas simples e complexos.
Aprendizagem por reforço
Embora as técnicas SV e ASV melhorem a eficiência do modelo, elas exigem uma grande quantidade de dados rotulados manualmente. Para atenuar esse problema, os pesquisadores propõem “otimização de política com orçamento de inferência restrito” (IBPO), um algoritmo de aprendizado por reforço que ensina o modelo a ajustar o comprimento dos caminhos de raciocínio com base na dificuldade da consulta.
O IBPO foi projetado para permitir que grandes modelos de linguagem (LLMs) melhorem suas respostas, permanecendo dentro das restrições do orçamento de inferência. O algoritmo de aprendizado por reforço permite que o modelo exceda os ganhos obtidos pelo treinamento em dados rotulados manualmente, gerando continuamente trajetórias ASV, avaliando respostas e selecionando resultados que fornecem a resposta correta e o orçamento de inferência ideal.
Seus experimentos mostram que o IBPO melhora a frente de Pareto, o que significa que, para um orçamento de inferência fixo, um modelo treinado no IBPO supera outras linhas de base.
Essas descobertas surgem em meio a alertas de pesquisadores de que os modelos atuais de IA estão com dificuldades. À medida que as empresas lutam para encontrar dados de treinamento de alta qualidade e explorar maneiras alternativas de melhorar seus modelos.
Uma solução promissora é o aprendizado por reforço, em que o modelo recebe uma meta e pode encontrar suas próprias soluções, em oposição ao ajuste fino supervisionado (SFT), em que o modelo é treinado em exemplos rotulados manualmente.
Surpreendentemente, o modelo frequentemente encontra soluções que os humanos não haviam pensado. Esta é uma fórmula que parece ter funcionado com o DeepSeek-R1, que desafiou o domínio dos laboratórios de IA americanos.
Os pesquisadores observam que "os métodos baseados em prompts e a TFS lutam para alcançar otimização e eficiência absolutas, corroborando a conjectura de que a TFS por si só não permite capacidades de autocorreção. Essa observação também é corroborada por trabalhos concomitantes, que sugerem que esse comportamento de autocorreção surge espontaneamente durante a RL, em vez de ser gerado manualmente por prompts ou TFS."
Comentários estão fechados.