

Avaliação de desempenho de modelos destilados DeepSeek-R1 em GPQA usando Ollama e avaliações simples da OpenAI
Configure e execute o benchmark GPQA-Diamond em modelos DeepSeek-R1 destilados localmente para avaliar suas capacidades de inferência.
Lançamento do último modelo DeepSeek-R1 Amplamente repercutido na comunidade global de IA. Ela alcançou avanços comparáveis aos modelos de inferência do Meta e do OpenAI, e fez isso em uma fração do tempo e a um custo muito menor.
Mas, além das manchetes e do exagero online, como podemos avaliar as capacidades de inferência de um modelo usando critérios reconhecidos? Esta é uma questão importante para especialistas em IA.
A interface do usuário de Busca profunda Isso facilita a exploração de seus recursos, mas usá-lo programaticamente fornece insights mais profundos e integração mais suave em aplicativos do mundo real. Entender como esses modelos operam localmente também proporciona melhor controle e acesso offline.

Neste artigo, exploraremos como usar Ollama و avaliações simples da OpenAI Para avaliar as capacidades de inferência dos modelos destilados do DeepSeek-R1 com base no benchmark GPQA-Diamante famoso Este critério é considerado uma das ferramentas mais importantes para avaliar modelos de inteligência artificial no campo do raciocínio lógico.
Para você Link do repositório GitHub Acompanha este artigo.
(1) Quais são os modelos de raciocínio?
Modelos de inferência, como DeepSeek-R1 e modelos de série o da OpenAI (por exemplo, o1, o3), são modelos de linguagem grande (LLMs) treinados usando aprendizado de reforço para realizar inferência. Esses modelos são ferramentas avançadas no campo da inteligência artificial, representando o auge da evolução na capacidade das máquinas de pensar logicamente e resolver problemas complexos.
A heurística é caracterizada pelo pensamento profundo antes de responder, produzindo uma longa série de pensamentos internos antes de responder. Ele se destaca na resolução de problemas complexos, programação, raciocínio científico e planejamento de várias etapas de fluxos de trabalho de agentes. Esses recursos os tornam indispensáveis em áreas como desenvolvimento avançado de software, pesquisa científica e automação de processos complexos.
(2) O que é o modelo DeepSeek-R1?
DeepSeek-R1 é um modelo de linguagem grande (LLM) de código aberto de última geração, projetado especificamente para Raciocínio avançado. Apresentado em janeiro de 2025 no artigo de pesquisa "DeepSeek-R1: Aumentando o poder de inferência em grandes modelos de linguagem com aprendizado por reforço". DeepSeek-R1 é um modelo pioneiro no campo da inteligência artificial.
Este modelo é baseado em uma arquitetura de modelo de grande linguagem (LLM) com 671 bilhões de parâmetros e foi treinado usando aprendizado por reforço extensivo (RL) com base no seguinte caminho:
- Dois estágios de aumento visam descobrir padrões de raciocínio aprimorados e alinhá-los às preferências humanas.
- Dois estágios de ajuste fino supervisionado servem como semente para as capacidades de inferência e não inferência do modelo.
Para ilustrar, o DeepSeek treinou dois modelos:
- O primeiro modelo, DeepSeek-R1-Zero, é um modelo de inferência treinado usando aprendizagem por reforço e gera dados para treinar o segundo modelo, DeepSeek-R1.
- Ele consegue isso produzindo rastros de inferência, dos quais apenas saídas de alta qualidade são retidas com base em seus resultados finais.
- Isso significa que, diferentemente da maioria dos modelos, os exemplos de aprendizado por reforço (RL) neste pipeline de treinamento não são selecionados por humanos, mas são gerados pelo próprio modelo.
O resultado é que o modelo obteve desempenho semelhante aos modelos líderes, como Modelo o1 da OpenAI Em tarefas como matemática, programação e raciocínio complexo.
(3) Compreendendo o processo de destilação e os modelos destilados do DeepSeek-R1
Além do modelo completo, eles também disponibilizaram em código aberto seis modelos menores e densos (também chamados de DeepSeek-R1) de tamanhos diferentes (1.5B, 7B, 8B, 14B, 32B, 70B), destilados do DeepSeek-R1 com base em Qwen أو lhama Como modelo básico.
Destilação É uma técnica na qual um modelo menor (“aluno”) é treinado para replicar o desempenho de um modelo maior e mais poderoso que foi previamente treinado (“professor”).
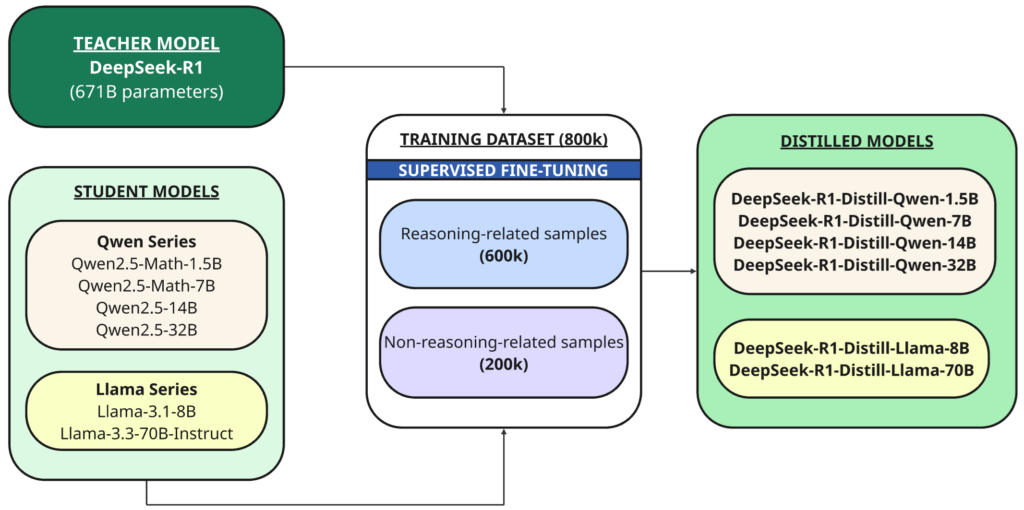
Neste caso, o professor é o modelo 1B DeepSeek-R671, e os alunos são os seis modelos destilados usando este modelo base de código aberto:
- Qwen2.5 — Matemática-1.5B
- Qwen2.5 — Matemática-7B
- Qwen2.5 — 14B
- Qwen2.5 — 32B
- Lhama-3.1 — 8B
- Lhama-3.3 — 70B-Instruir
O DeepSeek-R1 foi usado como modelo de professor para gerar 800,000 amostras de treinamento, uma mistura de amostras de inferência e não inferência, para destilação por meio de ajuste fino supervisionado Para modelos básicos (1.5B, 7B, 8B, 14B, 32B e 70B).
Então, por que destilamos em primeiro lugar?
O objetivo é transferir os recursos de inferência de modelos maiores, como o DeepSeek-R1 671B, para modelos menores e mais eficientes. Isso permite que modelos menores lidem com tarefas de inferência complexas, sendo mais rápidos e eficientes em termos de recursos.
Além disso, o DeepSeek-R1 tem um número enorme de parâmetros (671 bilhões), o que dificulta sua execução na maioria dos dispositivos de consumo.
Mesmo o mais potente MacBook Pro, com memória unificada máxima de 128 GB, não é suficiente para rodar um modelo com parâmetros de 671 bilhões.
Dessa forma, modelos destilados abrem a possibilidade de implantação em dispositivos com recursos computacionais limitados.
Alcançado Despreguiça Uma conquista notável ao quantizar o modelo original DeepSeek-R1 de 671 bilhões de parâmetros para apenas 131 GB — uma notável redução de 80% no tamanho. No entanto, o requisito de 131 GB de VRAM continua sendo um obstáculo significativo, especialmente para desenvolvedores que trabalham em dispositivos com recursos limitados. Essa conquista representa um passo significativo para tornar grandes modelos de IA acessíveis a uma gama maior de usuários.
(4) Seleção do modelo destilado ideal
Com seis tamanhos diferentes de modelos destilados para escolher, determinar o modelo certo depende em grande parte da capacidade do seu equipamento local.
Para aqueles com GPUs ou CPUs de alto desempenho que precisam de desempenho máximo, os modelos maiores DeepSeek-R1 (32B e superiores) são ideais – até mesmo a versão quântica 671B é viável.
No entanto, se os recursos forem limitados ou você preferir tempos de construção mais rápidos (como eu), variantes destiladas menores, como 8B ou 14B, são uma opção melhor. Isso equilibra o desempenho e os requisitos de recursos.
Para este projeto, usarei o modelo DeepSeek-R1 destilado. Qwen-14B, que corresponde às limitações de hardware que você encontrou. Este modelo (14B) representa um excelente compromisso entre precisão e velocidade, tornando-o perfeito para meu ambiente de desenvolvimento.
(5) Critérios para avaliar a capacidade de inferência de grandes modelos de linguagem
Grandes modelos de linguagem (LLMs) são normalmente avaliados usando métricas padronizadas que determinam seu desempenho em várias tarefas, incluindo compreensão da linguagem, geração de código, seguimento de instruções e resposta a perguntas. Exemplos comuns incluem métricas como: MMLUو Avaliação Humanaو MGSM. Essas métricas são essenciais para avaliar as capacidades de grandes modelos de linguagem.
Para medir a capacidade de raciocínio de um grande modelo de linguagem, precisamos de parâmetros mais desafiadores que se concentrem bastante no raciocínio e vão além de tarefas superficiais. Aqui estão alguns exemplos comuns que se concentram na avaliação de habilidades avançadas de raciocínio:
(i) Exame AIME 2024: Matemática Competitiva
- Preparar Exame Americano de Matemática por Convite (AIME) 2024 Um benchmark robusto para avaliar as capacidades de grandes modelos de linguagem (LLMs) no raciocínio matemático.
- Este exame representa um desafio significativo em matemática competitiva, pois apresenta problemas complexos e de várias etapas. O exame testa a capacidade de grandes modelos de linguagem de entender questões complexas, aplicar raciocínio avançado e realizar manipulações simbólicas precisas. O AIME é uma medida importante para avaliar habilidades complexas de resolução de problemas matemáticos.
(ii) Codeforces – Código da Concorrência
- Levante-se Padrão Codeforces Avaliar a capacidade de inferência de um grande modelo de linguagem (LLM) usando problemas de programação competitiva do mundo real da Codeforces, uma plataforma conhecida por desafios algorítmicos. Codeforces é o padrão ouro para avaliar as capacidades dos modelos de IA para resolver problemas complexos.
- Esses problemas testam a capacidade de um grande modelo de linguagem (LLM) de entender instruções complexas, executar raciocínio lógico e matemático, planejar soluções de várias etapas e gerar código correto e eficiente. Esses problemas exigem uma compreensão profunda de algoritmos e estruturas de dados, bem como a capacidade de traduzir o problema em código executável.
(iii) GPQA Diamond – questões científicas de nível de doutorado
- GPQA-Diamond é um subconjunto selecionado de As perguntas mais difíceis Do padrão GPQA (Perguntas e Respostas de Física de Pós-Graduação) O mais amplo e projetado especificamente para ampliar os limites da capacidade dos modelos de LLM de inferir em tópicos avançados de nível de doutorado. Este padrão representa um verdadeiro desafio à capacidade da IA de entender e inferir conceitos científicos complexos.
- Enquanto o GPQA inclui um conjunto de questões de pós-graduação conceituais e baseadas em cálculos, o GPQA-Diamond isola apenas as questões mais desafiadoras e aquelas que exigem raciocínio intensivo.
- Este critério é considerado “resistente ao Google”, o que significa que é difícil de responder mesmo com acesso irrestrito à web. Isso o torna uma ferramenta valiosa para avaliar a capacidade de grandes modelos de linguagem raciocinarem de forma independente.
- Aqui está um exemplo de uma questão GPQA-Diamond:
### GPQA Diamond - Pergunta de exemplo (Biologia Molecular) Uma célula eucariótica desenvolveu um mecanismo para transformar blocos de construção macromoleculares em energia. O processo ocorre nas mitocôndrias, que são fábricas de energia celular. Na série de reações redox, a energia dos alimentos é armazenada entre os grupos fosfato e usada como moeda celular universal. As moléculas carregadas de energia são transportadas para fora da mitocôndria para atuar em todos os processos celulares. Você descobriu um novo medicamento antidiabetes e quer investigar se ele tem efeito nas mitocôndrias. Você montou uma série de experimentos com sua linhagem celular HEK293. Qual dos experimentos listados abaixo não ajudará você a descobrir o papel mitocondrial do seu medicamento: (A) Extração de mitocôndrias por centrifugação diferencial seguida pelo kit de ensaio colorimétrico de captação de glicose (B) Citometria de fluxo após marcação com 2.5 µM de iodeto de 5,5',6,6'-tetracloro-1,1',3,3'-tetraetilbenzimidazolilcarbocianina (C) Transformação de células com luciferase recombinante e leitura no luminômetro após adição de 5 µM de luciferina ao sobrenadante (D) Microscopia de fluorescência confocal após coloração das células com Mito-RTP
Neste projeto, Usamos o GPQA-Diamond como padrão para conclusão., como eu usei OpenAI و DeepSeek Para avaliar seus modelos de inferência. A escolha do GPQA-Diamond como padrão de avaliação é uma evidência de sua dificuldade e importância no campo do desenvolvimento de IA.
(6) Ferramentas utilizadas
Neste projeto, usamos principalmente Ollama و avaliações simples Da OpenAI. Ollama é uma plataforma poderosa para executar grandes modelos de linguagem localmente, enquanto simple-evals fornece uma estrutura para avaliar o desempenho desses modelos.
(i) Ollama
Ollama É uma ferramenta de código aberto que simplifica a execução de grandes modelos de linguagem (LLMs) em nosso computador ou em um servidor local. Olama é uma plataforma ideal para executar modelos de IA localmente.
Ele atua como um gerenciador e tempo de execução, lidando com tarefas como downloads e configuração do ambiente. Isso permite que os usuários interajam com esses modelos sem a necessidade de uma conexão constante com a internet ou de depender de serviços em nuvem. Gerenciar modelos de linguagem grandes (LLMs) locais é um recurso essencial do Olama.
Ele suporta muitos modelos de linguagem de código aberto, incluindo DeepSeek-R1, e é compatível com várias plataformas: macOS, Windows e Linux. Além disso, ele oferece configuração simples, com o mínimo de complicações e uso eficiente de recursos. O Ollama permite que você aproveite o poder da inteligência artificial diretamente no seu dispositivo.
ImportanteCertifique-se de que sua máquina local tenha: Acessibilidade da GPU Para Ollama, isso acelera significativamente o desempenho e torna o benchmarking subsequente mais eficiente em comparação à CPU. Execute o comando
nvidia-smiNo terminal para verificar se a GPU foi detectada. Este procedimento garante que as capacidades do dispositivo sejam maximizadas para executar modelos com alta eficiência.
(ii) Biblioteca OpenAI simple-evals para avaliação de modelos de linguagem
Preparar avaliações simples Uma biblioteca leve projetada para avaliar modelos de linguagem usando metodologia de avaliação zero-shot com prompts de cadeia de pensamento. Esta biblioteca inclui benchmarks de avaliação populares, como MMLU, MATH, GPQA, MGSM e HumanEval, e tem como objetivo simular cenários de uso do mundo real para avaliar o desempenho de modelos de IA em tarefas de inferência complexas.
Alguns de vocês podem estar familiarizados com a biblioteca de avaliação mais popular e abrangente da OpenAI chamada avaliações, que é diferente de simple-evals.
Na verdade, a página indica README A especificação simple-evals indica que ela não tem a intenção de substituir a biblioteca. avaliações.
Então, por que usamos simple-evals?
A resposta simples é que avaliações simples Ele vem com textos de avaliação integrados para os padrões de inferência que almejamos (como GPQA), que não estão disponíveis na biblioteca. avaliações.
Além disso, não encontrei nenhuma outra ferramenta ou plataforma, além do simple-evals, que forneça uma maneira direta e nativa na linguagem. Python Para executar muitos padrões importantes, como GPQA, especialmente ao trabalhar com Ollama.
(7) Resultados da avaliação
Como parte da avaliação, selecionei: 20 perguntas aleatórias Do conjunto de 198 questões do GPQA-Diamond para trabalhar Formulário 14B Destilador. Foram necessários um total de 216 minutos, ou aproximadamente 11 minutos por pergunta.
O resultado foi um tanto decepcionante, pois registrou 10% Somente, o que é significativamente menor do que o resultado relatado de 73.3% para o modelo 1B DeepSeek-R671.
O principal problema que notei é que durante o raciocínio interno intensivo, O modelo frequentemente falhava em produzir qualquer resposta (por exemplo, retornando códigos de inferência como linhas finais de saída) ou fornecia uma resposta que não correspondia ao formato de múltipla escolha esperado (por exemplo, resposta: A).
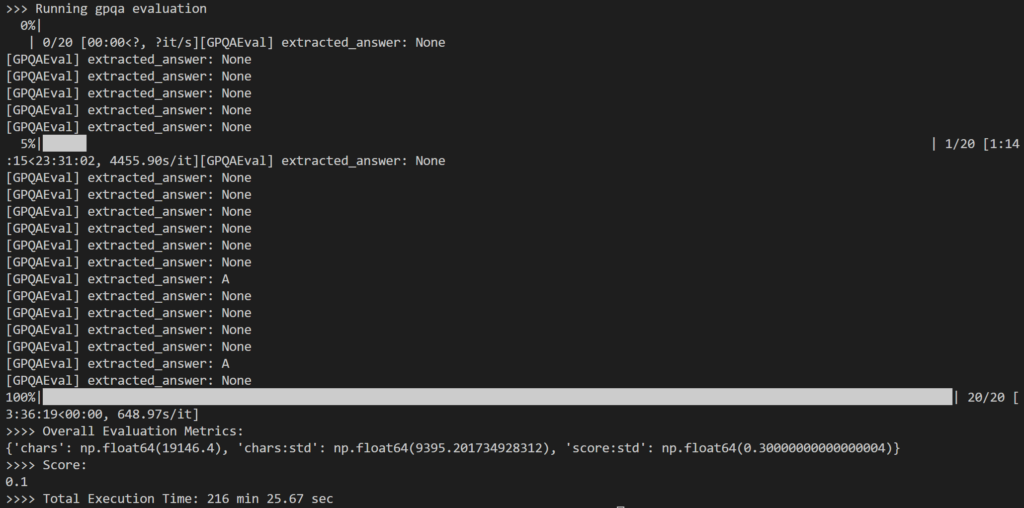
Como mostrado acima, muitas das saídas acabaram como: None Porque a lógica regex em simple-evals não conseguiu detectar o padrão de resposta esperado na resposta LLM.
Enquanto isso raciocínio humano Foi interessante observar, pois eu esperava um desempenho melhor em termos de precisão nas respostas às perguntas.
Também vi usuários on-line mencionando que mesmo o modelo maior 32B não funciona tão bem quanto o o1. Isso levantou dúvidas sobre a utilidade dos modelos de inferência destilados, especialmente quando eles têm dificuldade em fornecer respostas corretas, apesar de gerarem longas inferências.
No entanto, o GPQA-Diamond é um benchmark muito exigente, então esses modelos ainda podem ser úteis para tarefas de inferência mais simples. Seus menores requisitos computacionais também o tornam mais fácil.
Além disso, a equipe do DeepSeek recomendou executar vários testes e calcular a média dos resultados como parte do processo de benchmarking — algo que negligenciei devido a restrições de tempo.
(8) Guia detalhado passo a passo
Até aqui, abordamos os conceitos básicos e as principais conclusões.
Se você estiver pronto para uma experiência técnica prática, esta seção fornece uma visão aprofundada dos mecanismos internos e da implementação passo a passo. Este guia técnico prático fornecerá uma compreensão abrangente de como o sistema funciona.
Para visualizar (ou copiar) Repositório complementar do GitHub A seguir. Os requisitos de configuração do ambiente virtual podem ser encontrados aqui. aqui.
(i) Configuração inicial – Ollama
Começamos baixando o Ollama. Visita
Página de download do Ollama, escolha seu sistema operacional e siga as instruções de instalação correspondentes.
Após a conclusão da instalação, inicie o Ollama clicando duas vezes no aplicativo Ollama (para Windows e macOS) ou executando o comando ollama serve No terminal.
(ii) Configuração inicial – OpenAI simple-evals
A configuração simple-evals é relativamente única.
Embora simple-evals se apresente como uma biblioteca, A ausência de arquivos __init__.py No repositório significa que ele não está estruturado como um pacote Python adequado., levando a erros de importação após clonar o repositório localmente. Isso significa que não é um pacote Python padrão no sentido comumente usado em engenharia de software.
Como também não é publicado no PyPI e não possui arquivos de empacotamento padrão como setup.py أو pyproject.tomlNão pode ser instalado via pip. Isso torna o processo um pouco desafiador para novos desenvolvedores.
Felizmente, podemos usar Submódulos Git Como uma solução alternativa direta. Esses módulos permitem que você inclua um repositório Git dentro de outro, facilitando o gerenciamento de dependências.
“`html
Um submódulo Git nos permite incluir o conteúdo de outro repositório Git em nosso projeto. Ele extrai arquivos de um repositório externo (como simple-evals), mas mantém seu histórico separado.
Você pode escolher um dos dois métodos (A ou B) para extrair o conteúdo de simple-evals:
(a) Se você clonar meu repositório de projeto
Meu repositório de projeto já inclui simple-evals Como um submódulo, você pode simplesmente executar:
git submodule update --init --recursive(b) Se você estiver adicionando-o a um projeto recém-criado.
Para adicionar manualmente simple-evals como um submódulo, execute isto:
git submodule add https://github.com/openai/simple-evals.git simple_evalsNota: que simple_evals No final (com sublinhado) é muito importante. Ele especifica o nome da pasta, usando um hífen (ou seja, simples-evals) podem levar a problemas de importação mais tarde.
Etapa final (para ambos os métodos)
Depois de puxar o conteúdo do repositório, você deve criar um arquivo. __init__.py Vazio na pasta simple_evals O recém-criado pode ser importado como uma unidade. Você pode criá-lo manualmente ou usar o seguinte comando:
touch simple_evals/__init__.py(iii) Extraindo o modelo DeepSeek-R1 via Ollama
O próximo passo é baixar o modelo destilado localmente de sua escolha (por exemplo, 14B) usando este comando:
Uma lista de modelos DeepSeek-R1 disponíveis pode ser encontrada no Ollama. aqui. Para melhor desempenho, é recomendável usar a versão mais recente do modelo.
ollama pull deepseek-r1:14b(Quarto) Especifique as configurações
Definimos os parâmetros no arquivo YAML de configurações, conforme mostrado abaixo:
# config/config.yaml MODEL_NAME: "deepseek-r1:14b" # Nome do modelo (corresponde à lista de modelos Ollama) MODEL_TEMPERATURE: 0.6 # Definido entre 0.5 e 0.7 para DeepSeek-R1 EVAL_BENCHMARK: "gpqa" GPQA_VARIANT: "diamond" EVAL_N_EXAMPLES: 20
A temperatura do modelo está definida para 0.6 (Comparado ao valor padrão típico de 0). Isso segue as recomendações de uso do DeepSeek, que sugerem uma faixa de temperatura de 0.5 a 0.7 (0.6 é o recomendado). Para evitar repetições infinitas ou resultados incoerentes. Esta configuração é necessária para melhorar a qualidade da saída e garantir sua consistência.
Não perca a oportunidade de conferir Recomendações de uso exclusivas e interessantes do DeepSeek-R1 – especialmente para benchmarks – para garantir desempenho ideal ao usar modelos DeepSeek-R1.
EVAL_N_EXAMPLES Este é o parâmetro usado para definir o número de perguntas do conjunto completo de 198 perguntas usadas na avaliação. Este parâmetro é necessário para ajustar o processo de avaliação de acordo com os recursos disponíveis e os objetivos específicos do teste.
(v) Configurando o código do Sampler
Para oferecer suporte a modelos de linguagem baseados em Ollama dentro da estrutura simple-evals, criamos uma classe wrapper personalizada chamada OllamaSampler E guarde isso dentro utils/samplers/ollama_sampler.py. O amostrador é um componente essencial para testar e avaliar o desempenho de modelos de linguagem.
# utils/samplers/ollama_sampler.py importar ollama classe OllamaSampler: def __init__(self, model_name=None, temperature=0): self.model_name = model_name self.temperature = temperature def __call__(self, prompt_messages): prompt_text = prompt_messages[-1]["content"] resposta = ollama.chat( modelo=self.model_name, mensagens=[{"role": "user", "content": prompt_text}], opções={"temperature": self.temperature} ) conteúdo_da_resposta = resposta["mensagem"]["content"] retornar conteúdo_da_resposta def _pack_message(self, conteúdo, função): retornar {"função": função, "conteúdo": conteúdo}
Neste contexto, significa amostrador (Amplificador) Uma classe Python que gera saída de um modelo de linguagem com base em um prompt fornecido. Esta ferramenta é crucial para garantir que respostas diversas e representativas sejam geradas a partir do modelo.
Como os amostradores em simple-evals cobrem apenas provedores como OpenAI e Claude, precisamos de uma classe de amostrador que forneça uma interface compatível com Ollama. Isso garante uma integração perfeita com a estrutura de avaliação.
Levante-se OllamaSampler Extrai um prompt de pergunta do GPQA, envia-o ao formulário em uma temperatura especificada e retorna uma resposta em texto simples. A temperatura é um parâmetro importante que controla a aleatoriedade da saída.
Método incluído _pack_message Para garantir que o formato de saída corresponda ao que os scripts de avaliação em simple-evals esperam. Isso garante consistência e facilidade de análise.
6. Crie um roteiro de avaliação
O código a seguir demonstra como configurar a implementação de avaliação em um arquivo. main.py, incluindo o uso da categoria GPQAEval Da biblioteca simple-evals para executar testes de benchmark GPQA.
Função run_eval() É uma ferramenta de avaliação de tempo de execução configurável que testa grandes modelos de linguagem (LLMs) por meio do Ollama em relação a padrões como o GPQA. Esta função é necessária para avaliar com precisão o desempenho dos modelos.
# main.py def run_eval(): start_time = time.time() # Carregar arquivo de configuração config = load_config("config/config.yaml") # Inicializar o amostrador Ollama (wrapper em torno do bate-papo Ollama) ollama_sampler = OllamaSampler(model_name=config["MODEL_NAME"], temperature=config["MODEL_TEMPERATURE"] ) # Selecionar classe de avaliação a ser usada com base em EVAL_BENCHMARK eval_benchmark = config["EVAL_BENCHMARK"] # GPQA print(f">>> Executando {eval_benchmark} avaliação") if eval_benchmark == "gpqa": eval_class = GPQAEval eval_kwargs = { "n_repeats": config["EVAL_N_REPEATS"], # Padrão 1 "num_examples": config["EVAL_N_EXAMPLES"], # Definir como 20 "variant": config["GPQA_VARIANT"], # Subconjunto GPQA-Diamond } else: raise ValueError( f"Unknown EVAL_BENCHMARK '{eval_benchmark}'." ) # Instanciar e executar a avaliação apropriada evaluator = eval_class(**eval_kwargs) results = evaluator(ollama_sampler) # Executar avaliação com sampler end_time = time.time() elapsed_seconds = end_time - start_time minutes, seconds = divmod(elapsed_seconds, 60) # Calcular o tempo total gasto # O resultado retornado é um EvalResult que inclui uma lista de SingleEvalResult e métricas agregadas print(">>>> Métricas de Avaliação Geral:", results.metrics) print(">>>> Pontuação:", results.score) print(f">>>> Tempo Total de Execução: {int(minutos)} min {segundos:.2f} seg") if __name__ == "__main__": # Executar avaliação GPQA run_eval()
A função carrega as configurações do arquivo de configuração, configura a classe de avaliação apropriada de simple-evals e executa o modelo por meio de um processo de avaliação uniforme. Ele é salvo em um arquivo. main.py, que pode ser executado usando o comando python main.py. Isso garante um processo de avaliação consistente e repetível.
Seguindo os passos acima, configuramos e executamos com sucesso o benchmark GPQA-Diamond no modelo destilado DeepSeek-R1. Esse processo fornece insights valiosos sobre os recursos do modelo.
O resultado final
Neste artigo, exploramos como podemos combinar ferramentas como Ollama e simple-evals da OpenAI para explorar e avaliar modelos destilados do DeepSeek-R1, com foco em Avaliação de desempenho de grandes modelos de linguagem.
Os modelos destilados podem ainda não corresponder ao modelo original de 671 bilhões de parâmetros em benchmarks de inferência desafiadores como o GPQA-Diamond. No entanto, isso ilustra como a destilação pode expandir o acesso aos recursos de inferência de grandes modelos de linguagem (LLMs). Melhorando o acesso a grandes modelos de linguagem É um objetivo importante nesta área.
Apesar do desempenho inferior em tarefas complexas de nível de doutorado, essas variantes menores ainda podem ser aplicáveis em cenários menos exigentes, abrindo caminho para uma implantação local eficiente em uma gama mais ampla de dispositivos. Isso contribui para Implante grandes modelos de linguagem localmente Eficientemente.
Comentários estão fechados.