

Alcançando certeza em grandes modelos de linguagem (LLMs) usando circuitos inteligentes de tomada de decisão
A incerteza não é novidade na tecnologia: todos os sistemas modernos superam entradas e saídas incertas usando estruturas de controle matematicamente comprovadas.
A promessa dos agentes de IA conquistou o mundo. Os agentes podem interagir com o mundo ao seu redor, escrever artigos (mas não este), tomar ações em seu nome e, em geral, tornar a parte difícil de automatizar qualquer tarefa fácil e acessível.
Os agentes focam nas partes mais difíceis das operações e resolvem os problemas rapidamente. Às vezes, rápido demais – Se o seu processo baseado em agentes exigir um ser humano no circuito para decidir sobre o resultado, o estágio de revisão humana pode se tornar um gargalo no processo.
Um exemplo de processo baseado em agente é o processamento e a classificação de chamadas telefônicas de clientes. Mesmo um agente com 99.95% de precisão cometerá 5 erros ao ouvir 10,000 chamadas. Apesar de saber disso, o agente não pode lhe contar. Qual 5 em cada 10,000 chamadas foram classificadas incorretamente.

A técnica “LLM como Juiz” é uma técnica em que você alimenta cada entrada em outro processo LLM para avaliar se a saída proveniente da entrada está correta. No entanto, como este é outro processo de LLM, ele também pode ser impreciso. Essas duas operações probabilísticas criam uma matriz de confusão com verdadeiros positivos, falsos negativos, verdadeiros negativos e falsos positivos.
Em outras palavras, uma entrada que é classificada corretamente por um processo LLM pode ser julgada incorreta pelo seu juiz LLM ou vice-versa.
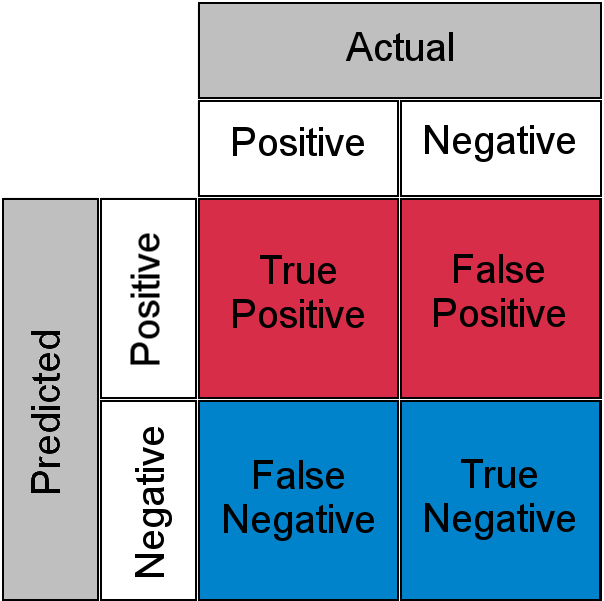
devido a esta " O desconhecido conhecido Para uma carga de trabalho sensível, um humano precisa revisar e entender todas as 10,000 chamadas. Voltamos ao mesmo problema de gargalo.
Como podemos incorporar mais certeza estatística em nossos processos orientados por agentes? Neste artigo, construo um sistema que nos permite ter mais certeza em nossos processos orientados por agentes, generalizá-lo para um número arbitrário de agentes e desenvolver uma função de custo para ajudar a orientar investimentos futuros no sistema. O código que utilizo neste artigo está disponível no meu repositório. circuitos de decisão de IA.
Circuitos de tomada de decisão de IA
Detectar e corrigir erros não são conceitos novos. A correção de erros é crucial em áreas como eletrônica digital e analógica. Mesmo os avanços na computação quântica dependem da expansão das capacidades de correção e detecção de erros. Podemos nos inspirar nesses sistemas e implementar algo semelhante com agentes de IA. Por exemplo, você pode Algoritmos de inteligência artificial Utilização avançada de técnicas de correção de erros encontradas em sistemas de comunicação.
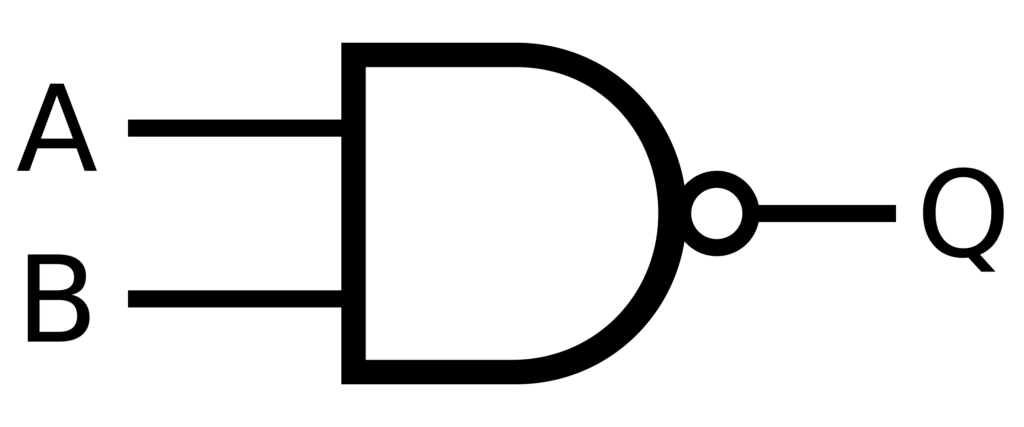
Na lógica booleana, as portas NAND são o Santo Graal da computação porque podem executar qualquer operação. Ele é funcionalmente completo, o que significa que qualquer operação lógica pode ser criada usando apenas portas NAND. Este princípio pode ser aplicado a sistemas de IA para criar estruturas robustas de tomada de decisão com correção de erros integrada. Isso permite a criação de redes neurais Mais confiável e capaz de lidar com dados incompletos ou ruidosos.
De circuitos eletrônicos a circuitos de tomada de decisão inteligente (IA)
Assim como os circuitos eletrônicos usam repetição e verificação para garantir cálculos confiáveis, os circuitos de tomada de decisão inteligente (IA) podem usar vários agentes com diferentes perspectivas para chegar a resultados mais precisos. Esses circuitos podem ser construídos usando princípios da teoria da informação e da lógica booleana:
- Processamento redundante: Vários agentes de IA processam as mesmas entradas de forma independente, semelhante a como as CPUs modernas usam circuitos redundantes para detectar erros de hardware. Este processo aumenta a confiabilidade do sistema de IA.
- Mecanismos de consenso: As saídas de decisão são combinadas usando sistemas de votação ou médias ponderadas, semelhantes às portas lógicas majoritárias em eletrônicos tolerantes a falhas. Esses mecanismos garantem que a decisão final reflita o consenso entre os agentes.
- Agentes Validadores: Os auditores especializados em IA verificam a razoabilidade da saída, trabalhando de forma semelhante aos códigos de detecção de erros, como Bits de paridade أو verificações de redundância cíclica (verificações CRC). Esses agentes reduzem a probabilidade de tomar decisões erradas.
- Integração Human-in-the-Loop: Verificação humana estratégica em pontos-chave do processo de tomada de decisão, semelhante a como os sistemas biométricos usam a supervisão humana como camada de verificação final. Isso garante que decisões importantes estejam sujeitas à avaliação humana.
Fundamentos matemáticos de circuitos de tomada de decisão em inteligência artificial
A confiabilidade desses sistemas pode ser determinada quantitativamente usando a teoria da probabilidade.
Por um lado, a probabilidade de falha advém da precisão observada ao longo do tempo em um conjunto de dados de teste, armazenado em um sistema como Lang Smith.

Para um fator de precisão de 90%, a probabilidade de falha, p_1، 1–0.9 É 0.1 ou 10%.

A probabilidade de dois fatores independentes falharem na mesma entrada é a probabilidade de ambos os fatores serem precisos multiplicada entre si:
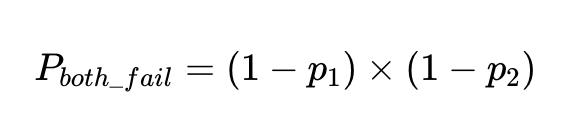
Se tivermos N execuções com esses clientes, o número total de falhas é
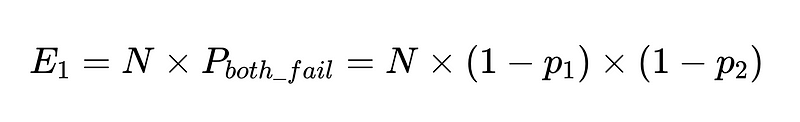
Portanto, para 10,000 execuções entre dois trabalhadores independentes com 90% de precisão, o número esperado de falhas é 100.
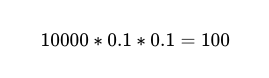
Contudo, ainda não sabemos. Qual Dessas 10,000 ligações, 100 são fracassos reais.
Podemos combinar quatro extensões dessa ideia para fornecer uma solução mais robusta que forneça confiança em qualquer resposta:
- Classificador Básico (Resolução Simples Acima)
- Backup (resolução simples acima)
- Verificador de esquema (resolução 0.7, por exemplo)

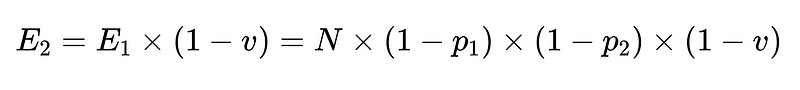
- Finalmente, um validador negativo (n = precisão 0.6 por exemplo)
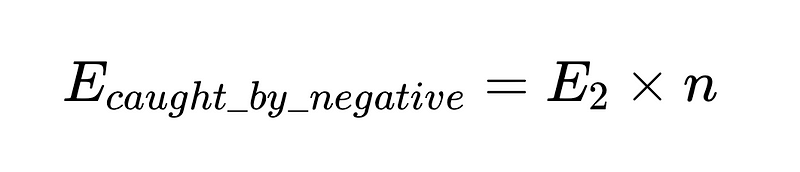
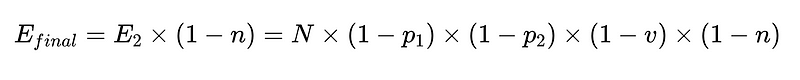
Para colocar isso em código (O armazém completo), podemos usar Python básico:
def primary_parser(self, customer_input: str) -> Dict[str, str]:
"""
Primary parser: Direct command with format expectations.
"""
prompt = f"""
Extract the category of the customer service call from the following text as a JSON object with key 'call_type'.
The call type must be one of: {', '.join(self.call_types)}.
If the category cannot be determined, return {{'call_type': null}}.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def backup_parser(self, customer_input: str) -> Dict[str, str]:
"""
Backup parser: Chain of thought approach with formatting instructions.
"""
prompt = f"""
First, identify the main issue or concern in the customer's message.
Then, match it to one of the following categories: {', '.join(self.call_types)}.
Think through each category and determine which one best fits the customer's issue.
Return your answer as a JSON object with key 'call_type'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def negative_checker(self, customer_input: str) -> str:
"""
Negative checker: Determines if the text contains enough information to categorize.
"""
prompt = f"""
Does this customer service call contain enough information to categorize it into one of these types:
{', '.join(self.call_types)}?
Answer only 'yes' or 'no'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
answer = response.content.strip().lower()
if "yes" in answer:
return "yes"
elif "no" in answer:
return "no"
else:
# Default to yes if the answer is unclear
return "yes"
@staticmethod
def validate_call_type(parsed_output: Dict[str, Any]) -> bool:
"""
Schema validator: Checks if the output matches the expected schema.
"""
# Check if output matches expected schema
if not isinstance(parsed_output, dict) or 'call_type' not in parsed_output:
return False
# Verify the extracted call type is in our list of known types or null
call_type = parsed_output['call_type']
return call_type is None or call_type in CALL_TYPESAo combinar essas operações com a lógica, Booleano Simplificando, podemos obter precisão semelhante junto com confiança em cada resposta:
def combine_results(
primary_result: Dict[str, str],
backup_result: Dict[str, str],
negative_check: str,
validation_result: bool,
customer_input: str
) -> Dict[str, str]:
"""
Combiner: Combines the results from different strategies.
"""
# If validation failed, use backup
if not validation_result:
if RobustCallClassifier.validate_call_type(backup_result):
return backup_result
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If negative check says no call type can be determined but we extracted one, double-check
if negative_check == 'no' and primary_result['call_type'] is not None:
if backup_result['call_type'] is None:
return {'call_type': None, "confidence": "low", "needs_human": True}
elif backup_result['call_type'] == primary_result['call_type']:
# Both agree despite negative check, so go with it but mark low confidence
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If primary and backup agree, high confidence
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "high"}
# Default: use primary result with medium confidence
if primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {'call_type': None, "confidence": "low", "needs_human": True}
Lógica de decisão: uma explicação passo a passo
Etapa 1: Quando o sistema de controle de qualidade falha
if not validation_result:Isso significa: “Se nosso especialista em controle de qualidade (auditor) rejeitar a análise inicial, não confie nele”. O sistema então tenta usar a opinião de apoio. Se isso também falhar na verificação, o caso será sinalizado para revisão por um especialista humano. Este procedimento garante que você não confie em dados imprecisos.
Em termos simples: "Se algo não estiver certo na nossa primeira resposta, vamos tentar o nosso método de backup. Se ainda houver dúvidas, vamos pedir a intervenção de um especialista humano." Isso garante que casos complexos sejam tratados corretamente.
Etapa 2: Abordar discrepâncias
if negative_check == 'no' and primary_result['call_type'] is not None:Esta etapa verifica um tipo específico de discrepância: “Nosso verificador negativo indica que não deveria haver um tipo de compra, mas nosso analista fundamentalista encontrou um tipo de venda mesmo assim”.
Nesses casos, o sistema depende do analista de fallback para atingir o ponto de equilíbrio:
- Se o analista de backup concordar que não há nenhum tipo de chamada, ela é enviada ao elemento humano.
- Se o analista de backup concordar com o analista principal, então ele é aceito, mas com confiança média.
- Se o analista de backup tiver um tipo de chamada diferente ← ele é enviado para o elemento humano
Isso é como dizer: “Se um especialista diz ‘isso é inclassificável’, mas outro diz que é, precisamos de um desempate ou de um juiz humano”. Este mecanismo é necessário para garantir uma classificação precisa do tipo de chamada e reduzir possíveis erros.
Etapa 3: Quando os especialistas concordam
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:Quando os analistas principal e de backup chegam independentemente à mesma conclusão, o sistema marca como “alta confiança” – este é o melhor cenário. Essa situação ideal ocorre quando múltiplas análises são conclusivamente consistentes.
Em termos simples: “Se dois especialistas diferentes, usando métodos diferentes, chegam independentemente à mesma conclusão, podemos estar bastante confiantes de que sua conclusão está correta.” Isso representa o consenso de especialistas, o que é um forte indicador de precisão e confiabilidade.
Etapa 4: Processamento padrão
Se nenhuma das condições especiais se aplicar, o sistema assume como padrão o resultado do analista primário com confiança “média”. Se o analista principal não conseguir identificar o tipo de chamada, ele sinaliza o caso para revisão por um analista humano especializado.
A importância desta abordagem na redução de erros
Essa lógica contribui para a construção de um sistema forte por:
- Reduzindo falsos positivosO sistema só oferece alta confiança quando vários métodos concordam, reduzindo bastante os alarmes falsos.
- Descobrindo contradiçõesQuando diferentes partes do sistema diferem, isso reduz a confiança ou encaminha o assunto para revisores humanos, garantindo que nenhum problema potencial seja ignorado.
- Escalada inteligenteOs revisores humanos só veem os casos que realmente precisam de sua expertise, aumentando a eficiência do processo de revisão e reduzindo o estresse dos recursos humanos.
- Designação de confiançaOs resultados incluem o nível de confiança do sistema, permitindo que processos subsequentes tratem resultados de alta confiança versus média confiança de forma diferente, o que é essencial para tomar decisões informadas.
Essa abordagem é semelhante à maneira como a eletrônica usa circuitos redundantes e mecanismos de votação para evitar que erros causem falhas no sistema. Em sistemas de IA, esse tipo de lógica de integração bem pensada pode reduzir significativamente as taxas de erro, ao mesmo tempo em que usa revisores humanos de forma eficiente apenas onde eles agregam mais valor. Isso garante que os recursos sejam otimizados e os erros sejam reduzidos simultaneamente, resultando em um sistema mais confiável e preciso.
Exemplo
Em 2015, o Departamento de Água da Cidade da Filadélfia publicou Estatísticas de chamadas de clientes por categoria. Entender as chamadas dos clientes é um processo muito comum que os agentes enfrentam. Em vez de ter um ser humano ouvindo cada chamada telefônica do cliente, um agente pode ouvir a chamada muito mais rapidamente, extrair informações e categorizar a chamada para análise posterior de dados. Para a gestão da água, isso é importante porque quanto mais cedo os problemas críticos forem identificados, mais cedo eles poderão ser resolvidos.
Podemos construir uma experiência. Usei um modelo de linguagem grande (LLM) para gerar transcrições falsas das ligações telefônicas em questão, perguntando: “Dada a seguinte classe, gere uma versão curta dessa ligação telefônica: Aqui estão alguns desses exemplos com o arquivo completo disponível. aqui:
{
"calls": [
{
"id": 5,
"type": "ABATEMENT",
"customer_input": "I need to report an abandoned property that has a major leak. Water is pouring out and flooding the sidewalk."
},
{
"id": 7,
"type": "AMR (METERING)",
"customer_input": "Can someone check my water meter? The digital display is completely blank and I can't read it."
},
{
"id": 15,
"type": "BTR/O (BAD TASTE & ODOR)",
"customer_input": "My tap water smells like rotten eggs. Is it safe to drink?"
}
]
}Agora, podemos configurar o experimento com uma avaliação mais tradicional usando um modelo de linguagem grande como juiz (Implementação completa aqui):
def classify(customer_input):
CALL_TYPES = [
"RESTORE", "ABATEMENT", "AMR (METERING)", "BILLING", "BPCS (BROKEN PIPE)", "BTR/O (BAD TASTE & ODOR)",
"C/I - DEP (CAVE IN/DEPRESSION)", "CEMENT", "CHOKED DRAIN", "CLAIMS", "COMPOST"
]
model = ChatAnthropic(model='claude-3-7-sonnet-latest')
prompt = f"""
You are a customer service AI for a water utility company. Classify the following customer input into one of these categories:
{', '.join(CALL_TYPES)}
Customer input: "{customer_input}"
Respond with just the category name, nothing else.
"""
# Get the response from Claude
response = model.invoke(prompt)
predicted_type = response.content.strip()
return predicted_typeAo passar apenas o texto para um grande modelo de linguagem (LLM), podemos isolar o verdadeiro conhecimento de classe da classe extraída que é retornada e comparar.
def compare(customer_input, actual_type)
predicted_type = classify(customer_input)
result = {
"id": call["id"],
"customer_input": customer_input,
"actual_type": actual_type,
"predicted_type": predicted_type,
"correct": actual_type == predicted_type
}
return resultExecutar isso em todo o conjunto de dados sintéticos usando o Claude 3.7 Sonnet (o modelo mais recente, até o momento) é de altíssimo desempenho, com 91% das chamadas sendo classificadas com precisão:
"metrics": {
"overall_accuracy": 0.91,
"correct": 91,
"total": 100
}Se essas fossem chamadas reais e não tivéssemos conhecimento prévio da categoria, ainda precisaríamos revisar todas as 100 chamadas telefônicas para encontrar as 9 chamadas classificadas incorretamente.
Ao aplicar nosso poderoso circuito de tomada de decisão acima, obtemos resultados de precisão semelhantes junto com Confiança Nessas respostas. Neste caso, uma precisão geral de 87%, mas uma precisão de 92.5% em nossas respostas de alta confiança.
{
"metrics": {
"overall_accuracy": 0.87,
"correct": 87,
"total": 100
},
"confidence_metrics": {
"high": {
"count": 80,
"correct": 74,
"accuracy": 0.925
},
"medium": {
"count": 18,
"correct": 13,
"accuracy": 0.722
},
"low": {
"count": 2,
"correct": 0,
"accuracy": 0.0
}
}
}Precisamos de 100% de precisão em nossas respostas de alta confiança, então ainda há trabalho a ser feito. O que esta abordagem nos permite fazer é mergulhar em razão Imprecisão de respostas de alta confiança. Nesse caso, alegações fracas e recursos de verificação simples não capturam todos os problemas, levando a erros de classificação. Esses recursos podem ser aprimorados iterativamente para atingir 100% de precisão em respostas de alta confiança.
Melhorias no sistema de filtragem para aumentar a confiança nos resultados.
O sistema atual classifica as respostas como “alta confiança” quando os analistas principal e de backup concordam. Para alcançar maior precisão, devemos ser mais seletivos sobre o que é considerado “alta confiança”.
# Modified high confidence logic
if (primary_result['call_type'] == backup_result['call_type'] and
primary_result['call_type'] is not None and
validation_result and
negative_check == 'yes' and
additional_validation_metrics > threshold):
return {'call_type': primary_result['call_type'], "confidence": "high"}Ao adicionar critérios de qualificação adicionais, obteremos menos resultados de “alta confiança”, mas eles serão mais precisos. Essa melhoria no sistema de filtragem visa reduzir erros e aumentar a confiabilidade dos dados classificados como de alta qualidade.
Técnicas de verificação adicionais: aumentando a precisão da análise
Aqui estão algumas outras ideias para aprimorar seu processo de validação e análise de dados:
Analisador TerciárioAdicione um terceiro método de análise independente. Este método serve como uma camada adicional de verificação, comparando os resultados de dois métodos analíticos diferentes com o resultado de um terceiro método, para garantir maior precisão e reduzir a possibilidade de erros.
# Only mark high confidence if all three agree
if primary_result['call_type'] == backup_result['call_type'] == tertiary_result['call_type']:Correspondência de padrões históricos:Compare os resultados com resultados historicamente corretos (pense em pesquisa vetorial). Essa técnica usa dados históricos confiáveis como referência e compara os resultados atuais a eles para identificar quaisquer desvios ou inconsistências. Pode ser considerada uma espécie de “memória” para análise, auxiliando na detecção de anomalias ou situações inesperadas.
if similarity_to_known_correct_cases(primary_result) > 0.95:Teste AdversarialAplique pequenas variações nas entradas e verifique se a classificação permanece estável. Este método visa testar a robustez e a solidez de um sistema de classificação expondo-o a pequenas alterações nos dados. Se o sistema for altamente sensível a essas mudanças, isso pode indicar possíveis fraquezas ou vieses.
variations = generate_input_variations(customer_input)
if all(analyze_call_type(var) == primary_result['call_type'] for var in variations):
Fórmula geral para intervenções humanas em um sistema de extração LLM
A derivação completa está disponível aqui..
- N = Número total de execuções (10,000 em nosso exemplo)
- p_1 = precisão do analisador base (0.8 em nosso exemplo)
- p_2 = precisão do analisador de fallback (0.8 em nosso exemplo)
- v = eficácia do validador de esquema (0.7 em nosso exemplo)
- n = eficácia do verificador negativo (0.6 em nosso exemplo)
- H = número de intervenções humanas necessárias
- E_final = erros finais não detectados
- m = número de auditores independentes
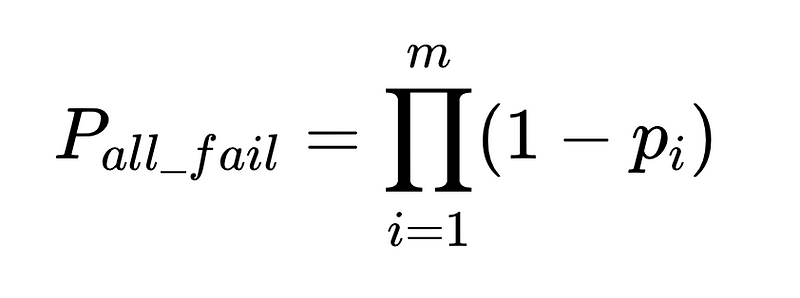
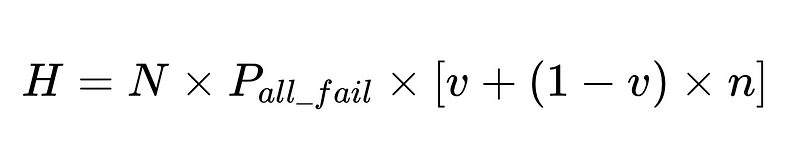
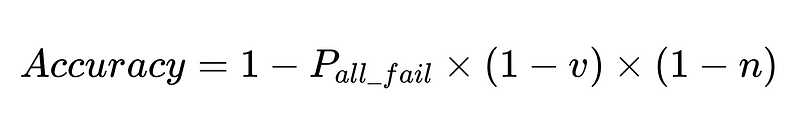
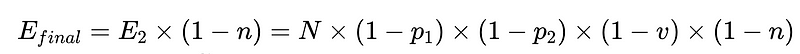
Projeto de sistema ideal
A equação revela insights importantes sobre a precisão de um sistema de processamento de linguagem natural (PLN):
- Adicionar analisadores reduz a sobrecarga, mas melhora a precisão geral.
- A precisão do sistema é limitada por:
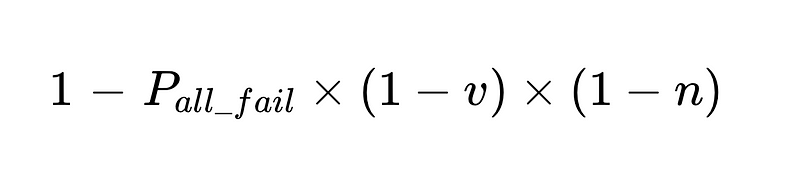
- As intervenções humanas são proporcionais Diretamente Com um total de N execuções.
Por exemplo:
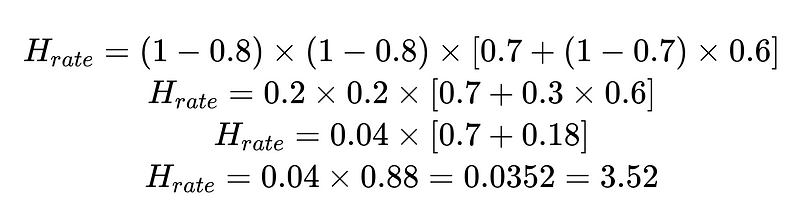
Podemos usar a taxa de intervenção humana calculada (H_rate) para rastrear a eficácia da nossa solução em tempo real. Se a taxa de intervenção humana começar a subir acima de 3.5%, saberemos que o sistema está falhando. Se a taxa de intervenção humana diminuir consistentemente para menos de 3.5%, saberemos que nossas otimizações estão funcionando conforme o esperado.
função de custo
Também podemos criar uma função de custo que nos ajude a melhorar nosso sistema. A função de custo é uma ferramenta analítica poderosa para avaliar o desempenho financeiro de um sistema e identificar possíveis áreas de melhoria.
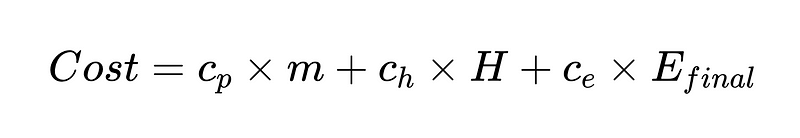
Nome:
- c_p = custo de execução por analisador (US$ 0.10 em nosso exemplo)
- m = número de vezes que o analisador é executado (em nosso exemplo 2 * N)
- H = Número de casos que requerem intervenção humana (352 do nosso exemplo)
- c_h = custo de uma intervenção humana (US$ 200 por exemplo: 4 horas a US$ 50/hora)
- c_e = custo de um erro não detectado (por exemplo, US$ 1000)
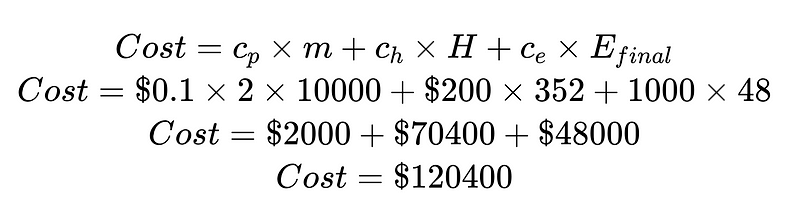
Ao dividir o custo pelo custo da intervenção humana e pelo custo de erros não detectados, podemos aprimorar o sistema como um todo. Neste exemplo, se o custo da intervenção humana (US$ 70,400) for indesejável e caro, podemos nos concentrar em aumentar os resultados de alta confiabilidade. Se o custo de erros não detectados (US$ 48,000) for indesejável e caro, podemos introduzir analisadores de sintaxe Plus para reduzir a taxa de erros não detectados.
É claro que as funções de custo são mais úteis como formas de explorar como melhorar as situações que elas descrevem.
A partir do cenário acima, para reduzir o número de erros não detectados, E_final, em 50%, onde
- p1 e p2 = 0.8,
- v = 0.7 e
- n = 0.6
Temos três opções:
- Adicionar um novo analisador gramatical com 50% de precisão e incluí-lo como analisador secundário. Observe que isso tem uma desvantagem: o custo de execução dos analisadores gramaticais Plus aumenta junto com o aumento do custo da intervenção humana.
- Melhorar os analisadores gramaticais existentes em 10% cada. Isso pode ou não ser possível devido à dificuldade da tarefa executada por esses analisadores sintáticos.
- Melhorar o processo de auditoria em 15%. Novamente, isso aumenta o custo por meio da intervenção humana.
O futuro da confiança na IA: construindo confiança por meio de extrema precisão
À medida que os sistemas de IA se tornam cada vez mais integrados aos aspectos vitais dos negócios e da sociedade, a busca pela precisão ideal se tornará cada vez mais imperativa, especialmente em aplicações críticas. Ao adotar essas abordagens inspiradas em circuitos para a tomada de decisões de IA, podemos construir sistemas que não apenas escalam com eficiência, mas também ganham a confiança profunda que só vem do desempenho consistente e confiável. O futuro não está em modelos individuais mais poderosos, mas em sistemas cuidadosamente projetados que combinam múltiplas perspectivas com supervisão humana estratégica.
Assim como a eletrônica digital evoluiu de componentes não confiáveis para criar computadores nos quais confiamos nossos dados mais importantes, os sistemas de IA agora estão em uma jornada semelhante. As estruturas descritas neste artigo representam os projetos para o que eventualmente se tornará a arquitetura padrão para IA de missão crítica — sistemas que não apenas prometem confiabilidade, mas a garantem matematicamente. A questão não é mais se podemos construir sistemas de IA com precisão quase perfeita, mas com que rapidez podemos implementar esses princípios em nossas aplicações mais importantes.
Comentários estão fechados.