

Melhorando a detecção em modelos Transformer adicionando ruído de treinamento
Os modelos de visão modernos do Transformer adicionam ruído para melhorar o desempenho de detecção de objetos 2D e 3D. Neste artigo, aprenderemos como esse mecanismo funciona e discutiremos sua contribuição para melhorar a precisão dos modelos de detecção de objetos, com foco no uso de técnicas como redução de ruído no processo de treinamento.

Modelos de transformadores para visão precoce
DETR – DEtection TRansformer (Carion, Massa et al. 2020), uma das primeiras arquiteturas Transformer para detecção de objetos, usou consultas de codificador-decodificador aprendidas para extrair informações de detecção de tokens de imagem. Essas consultas foram inicializadas aleatoriamente, e a Arquitetura não impôs nenhuma restrição que forçasse essas consultas a aprender objetos do tipo âncora. Embora tenha alcançado resultados semelhantes com o Faster-RCNN, sua desvantagem foi a convergência lenta – 500 épocas foram necessárias para treiná-lo (DN-DETR, Li et al., 2024). Arquiteturas mais recentes baseadas em DETR usaram agrupamento deformável que permitiu que as consultas se concentrassem apenas em regiões específicas na imagem (Zhu et al., Deformable DETR: Deformable Transformers For End-To-End Object Detection, 2020), enquanto outras (Liu et al., DAB-DETR: Dynamic Anchor Boxes Are Better Queries For DETR, 2022) usaram âncoras espaciais (geradas usando k-means, de maneira semelhante a como as CNNs baseadas em âncoras fazem), que foram codificadas nas consultas iniciais. As conexões de salto forçam o bloco decodificador do Transformer a aprender os quadrados como valores de inclinação das âncoras. Camadas de atenção deformáveis usavam âncoras pré-codificadas para amostrar características espaciais da imagem e usá-las para gerar tokens de atenção. Durante o treinamento, o modelo aprende as âncoras ideais para usar. Essa abordagem ensina o modelo a usar recursos como tamanho da caixa explicitamente em suas consultas.
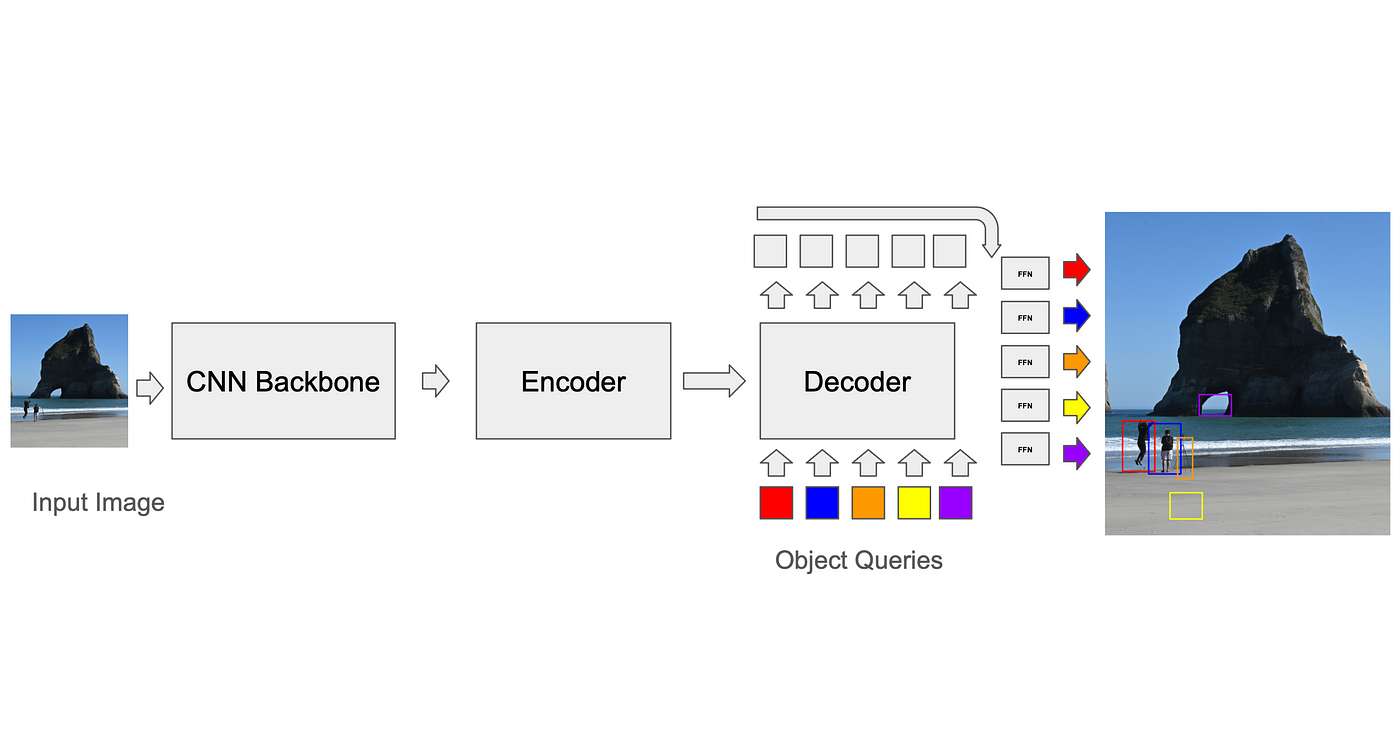
Correspondência de previsões com fatos concretos: algoritmo de correspondência binária
Para calcular a perda, o treinador primeiro precisa corresponder as previsões do modelo às caixas de verdade básica (GT). Embora CNNs baseadas em âncoras tenham soluções relativamente fáceis para esse problema (por exemplo, cada âncora só pode ser correspondida a caixas GT em seu voxel durante o treinamento e, na inferência, a supressão não máxima é usada para remover detecções sobrepostas), o padrão para transformadores, desenvolvido pelo DETR, é usar um algoritmo de correspondência binária chamado algoritmo húngaro. A cada iteração, o algoritmo encontra a melhor correspondência entre a previsão e a verdade básica (uma correspondência que otimiza uma função de custo, como a distância média quadrática entre os cantos das caixas, somada a todas as caixas). A perda entre os pares preditor-fundamental-verdade é então calculada e pode ser retropropagada. Previsões exageradas (previsões sem correspondência de GT) incorrem em uma perda discreta que os incentiva a reduzir sua pontuação de confiança. Este processo é necessário para melhorar a precisão do modelo e reduzir erros.
o problema
A complexidade de tempo do algoritmo húngaro é o(n³). Curiosamente, isso não é necessariamente um gargalo na qualidade do treinamento: The Stable Marriage Problem: An Interdisciplinary Review From The Physicist's Perspective, Fenoaltea et al., 2021, mostra que o algoritmo é instável, o que significa que uma pequena alteração em sua função objetivo pode levar a uma grande alteração em seu resultado correspondente, levando a objetivos de treinamento de consulta inconsistentes. As implicações práticas do treinamento de transformadores são que as consultas de objetos podem saltar entre objetos e leva muito tempo para aprender os melhores recursos para convergência. Em outras palavras, a instabilidade do algoritmo leva a oscilações no processo de treinamento, o que demanda mais tempo para atingir os melhores resultados.
DN-DETR (Detecção de Objetos por Eliminação de Ruído)
Li e outros. propôs uma solução elegante para o problema de correspondência instável, que mais tarde foi adotada em muitos outros trabalhos, incluindo DINO, Mask DINO, Group DETR e outros.
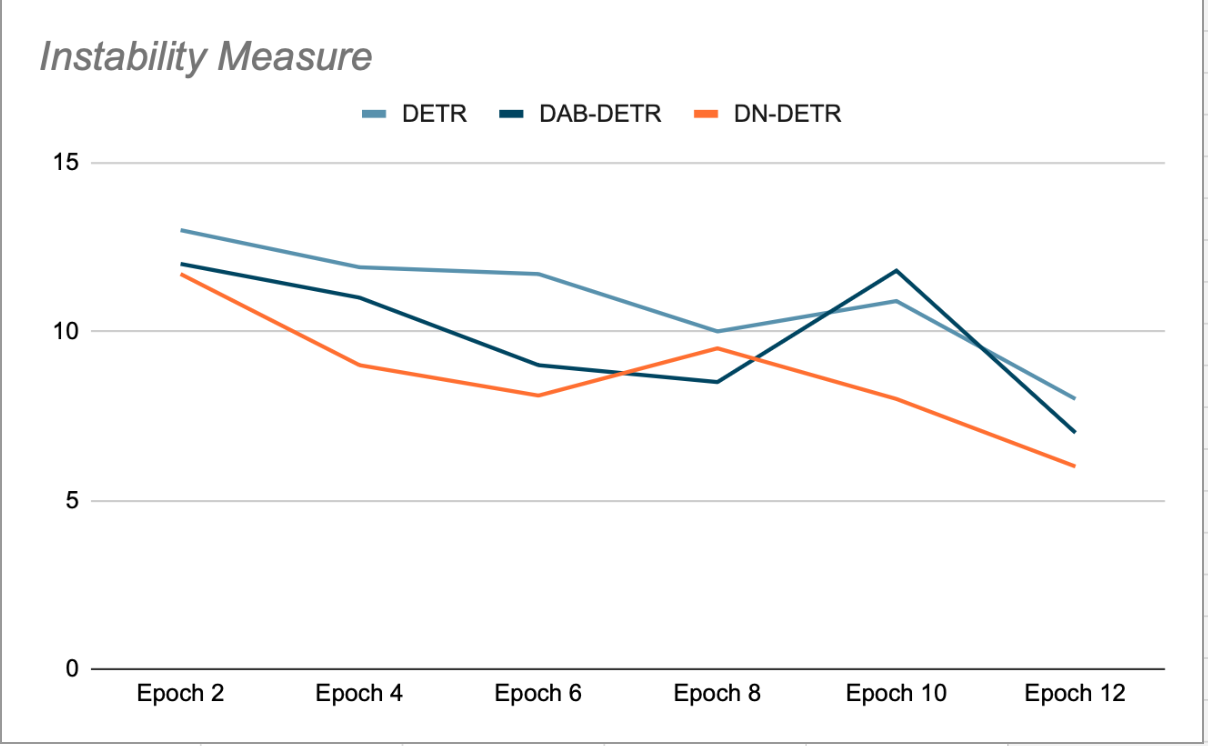
A ideia principal do DN-DETR é potencializar a formação através da criação Pontos de pivô imaginários fáceis de inclinarEle ignora o processo de correspondência. Isso é feito durante o treinamento adicionando uma pequena quantidade de ruído aos blocos GT (terra verdadeira) e alimentando esses blocos ruidosos como âncoras para consultas do decodificador. As consultas DN são mascaradas das consultas orgânicas e vice-versa, para evitar atenção cruzada que poderia interferir no treinamento. As detecções geradas por essas consultas já são correspondidas aos seus blocos GT de origem e não requerem correspondência bipartida. Os autores do DN-DETR mostraram que, durante as fases de validação ao final de cada época (onde a remoção de ruído é desativada), isso melhora a estabilidade do modelo em comparação com DETR e DAB-DETR, o que significa que as consultas Plus são consistentes em sua correspondência com o objeto GT em épocas sucessivas (ver Figura 2).
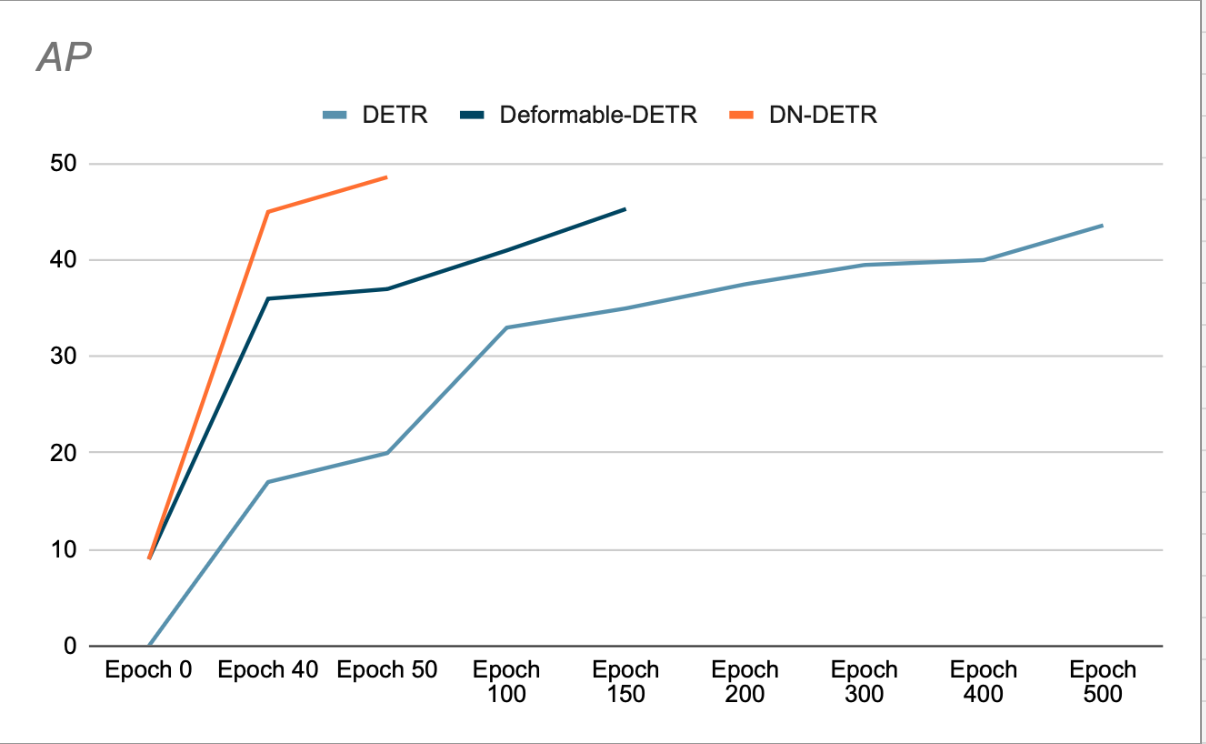
Os autores mostram que o uso de DN acelera a convergência e alcança melhores resultados de detecção. (Ver Figura 3). O estudo de remoção mostra um aumento de 1.9% na AP (precisão média) no conjunto de dados de detecção de COCO, em comparação ao SOTA anterior (DAB-DETR, AP 42.2%), ao usar o ResNet-50 como base.
DINO e remoção de ruído de contraste
O DINO desenvolveu ainda mais essa ideia, adicionando aprendizado contrastante ao mecanismo de remoção de ruído: além do exemplo positivo, o DINO cria outra versão com ruído de cada GT, que é matematicamente construída para estar mais distante do GT do que o exemplo positivo (veja a Figura 4). Esta versão é usada como um exemplo negativo para treinamento: o modelo aprende a aceitar a detecção mais próxima da verdade básica e rejeitar a detecção mais distante (aprendendo a prever a classe “nenhum objeto”).
Além disso, o DINO permite agrupamentos múltiplos para redução de ruído contrastante (CDN) – várias âncoras ruidosas para cada objeto GT – aproveitando ao máximo cada iteração de treinamento.
Os autores do DINO relataram uma precisão média (AP) de 49% (no COCO val2017) ao usar um CDN.
Modelos temporais modernos que precisam rastrear objetos de quadro a quadro, como o Sparse4Dv3, usam CDNs e adicionam grupos de redução de ruído temporal, onde algumas âncoras DN bem-sucedidas são armazenadas (junto com as âncoras não DN aprendidas) para uso em quadros subsequentes, o que melhora o desempenho do modelo no rastreamento de objetos.

مناقشة
A redução de ruído (DN) parece melhorar a velocidade de convergência e o desempenho final dos detectores de transformadores de visão. Entretanto, ao examinar o desenvolvimento dos vários métodos mencionados acima, surgem as seguintes questões:
- O DN melhora modelos que usam âncoras aprendíveis. Mas âncoras aprendíveis são realmente importantes? O DN também melhorará os modelos que usam âncoras não aprendíveis?
- A principal contribuição do DN para o treinamento é adicionar estabilidade ao processo de descida do gradiente, ignorando a correspondência bipartida. Mas a correspondência binária parece existir principalmente porque a norma no trabalho de transformadores é evitar restrições espaciais em consultas. Então, se restringirmos manualmente as consultas a locais de imagem específicos e abandonarmos a correspondência binária (ou usarmos uma versão simplificada da correspondência binária, que é executada em cada patch de imagem separadamente), o DN ainda melhorará os resultados?
Não consegui encontrar trabalhos que fornecessem respostas claras a essas perguntas. Minha hipótese é que um modelo que usa âncoras não aprendíveis (desde que as âncoras não sejam muito esparsas) e consultas espacialmente restritas, 1 – não exigirá um algoritmo de correspondência binária, e 2 – não se beneficiará do DN no treinamento, uma vez que as âncoras já são conhecidas e não há ganho na regressão de aprendizagem de outras âncoras efêmeras.
Se as âncoras estiverem fixas, mas dispersas, posso ver como o uso de âncoras efêmeras facilita a descida e pode proporcionar um início tranquilo ao processo de treinamento.
Anchor-DETR (Wand et al., 2021) compara a distribuição espacial de âncoras aprendíveis e não aprendíveis, e o desempenho dos respectivos modelos e, na minha opinião, a capacidade de aprendizagem não agrega muito valor ao desempenho do modelo. Vale ressaltar que eles usam o algoritmo húngaro em ambos os métodos, então não está claro se eles poderiam abandonar a correspondência binária e ainda manter o desempenho.
Uma consideração a ter em mente é que pode haver razões produtivas para evitar NMS na inferência, o que incentiva o uso do algoritmo húngaro no treinamento.
Onde a remoção de ruído pode realmente importar? Na minha opinião - em Rastreabilidade. No rastreamento, o modelo recebe um fluxo de vídeo e é necessário não apenas para detectar vários objetos em quadros consecutivos, mas também para manter a identidade exclusiva de cada objeto detectado. Modelos de transformadores temporais, ou seja, modelos que usam a natureza sequencial do streaming de vídeo, não processam quadros individuais de forma independente. Em vez disso, ele mantém um banco que armazena descobertas anteriores. No treinamento, o modelo de rastreamento é incentivado a regredir a partir da detecção anterior do objeto (ou mais precisamente, o fixador associado à detecção anterior do objeto), em vez de simplesmente regredir a partir do fixador mais próximo. Como a descoberta anterior não se restringe a alguma rede fixa de estabilizadores, é plausível que a flexibilidade estimulada pelo DN seja benéfica. Eu gostaria muito de ler trabalhos futuros que abordem essas questões.
Isso é tudo sobre remoção de ruído e sua contribuição para transformadores de visão! Se você gostou do meu artigo, você está convidado a visitar alguns dos meus outros artigos sobre aprendizado profundo e aprendizado de máquina e visão computacional!
Comentários estão fechados.