

Testei o novo recurso de geração de imagens nativas do Gemini e é absolutamente incrível.
Resumo:
- O Google lançou a geração e edição nativa de imagens usando o novo Gemini 2.0 Flash beta.
- O recurso já está disponível gratuitamente no AI Studio, e você pode gerar e editar uma série de imagens coordenadas usando comandos de texto simples.
- Você pode remover e adicionar elementos, inserir texto, colorir imagens, criar uma história visual e muito mais.
Ouvimos o termo "nativamente multimodal" em IA há mais de um ano, mas as empresas têm sido lentas em liberar todo o potencial multimodal de seus modelos de IA até agora. O Google finalmente lançou seu mais recente protótipo, o “Gemini 2.0 Flash Experimental”, com… Capacidade de gerar e editar imagens originaisOh.
Agora, você deve estar se perguntando: qual é a importância da geração de imagens? A geração de imagens de IA está disponível em todos os principais chatbots de IA, como o ChatGPT, há algum tempo. Bem, quando geramos imagens de IA no ChatGPT ou Gemini, elas são direcionadas para um modelo especializado baseado em difusão, como Dall-E 3 ou Imagen 3. Esses modelos são treinados em imagens e são projetados apenas para gerar imagens; É uma extensão do modelo principal de IA, não parte dele.
No entanto, modelos de visão linguística como Gemini Nativamente multimídia, o que significa que pode entender, gerar e modificar texto e imagens inerentemente. Até agora, nenhuma empresa de tecnologia disponibilizou esse recurso aos usuários. A OpenAI demonstrou seu recurso nativo de geração de imagens com o GPT-4o em 2024, mas, novamente, ele nunca foi lançado.
 Com o recurso de geração de imagem original, você obterá: Melhor coordenação Onde modelos multimodais são treinados em um enorme conjunto de dados de diferentes mídias. Como resultado, esses modelos têm uma melhor compreensão dos conceitos e demonstram um conhecimento mais amplo do mundo.
Com o recurso de geração de imagem original, você obterá: Melhor coordenação Onde modelos multimodais são treinados em um enorme conjunto de dados de diferentes mídias. Como resultado, esses modelos têm uma melhor compreensão dos conceitos e demonstram um conhecimento mais amplo do mundo.
Além de gerar imagens, você pode editá-las facilmente usando comandos de texto simples. Por exemplo, você pode carregar uma imagem e pedir ao modelo para adicionar óculos de sol, inserir texto em negrito, remover objetos e muito mais. Ao contrário dos modelos de difusão, que regeneram a imagem inteira a cada novo comando, os modelos multimídia nativos mantêm a consistência em várias edições.
Crie imagens usando a demonstração do Gemini 2.0 Flash
Atualmente, o recurso de criação de imagem original não está disponível para usuários públicos. A demonstração do Gemini 2.0 Flash com geração de imagem nativa está disponível apenas na plataforma AI Studio do Google (Visita) de graça.
Após a visualização do modelo no AI Studio, ele será lançado no Gemini para todos usarem em um futuro próximo. No entanto, testei o novo modelo Gemini com o recurso de criação de imagens e foi uma experiência muito emocionante.
Primeiro, comecei com um guia visual para mostrar a consistência da capacidade de geração de imagens do Gemini. Pedi à Gemini para criar um guia visual sobre como fazer uma omelete, criando uma foto para cada etapa do processo.
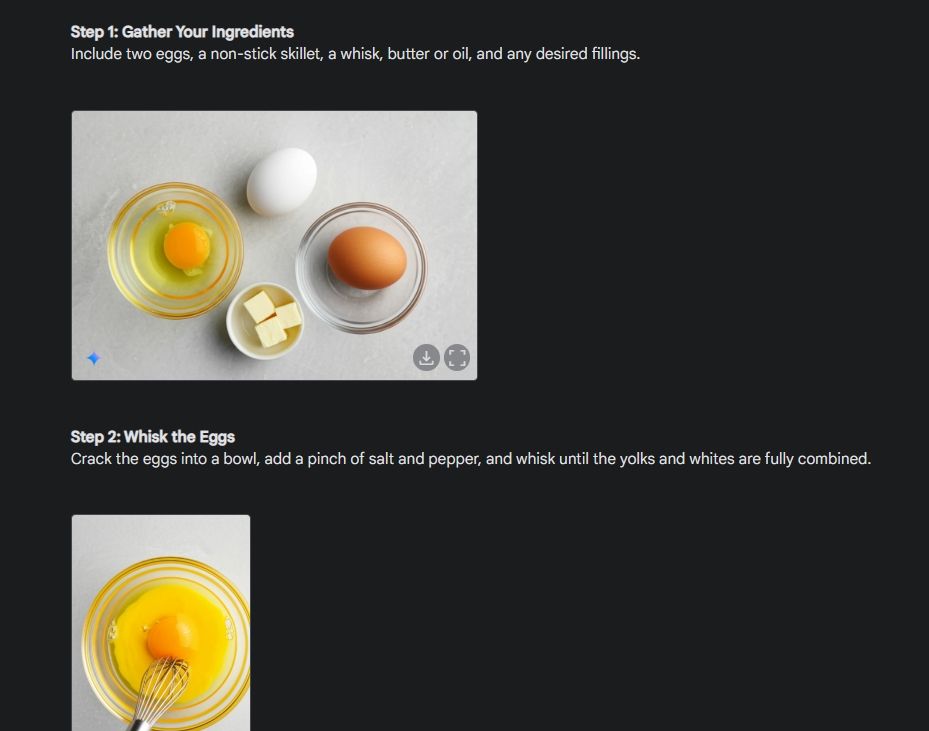
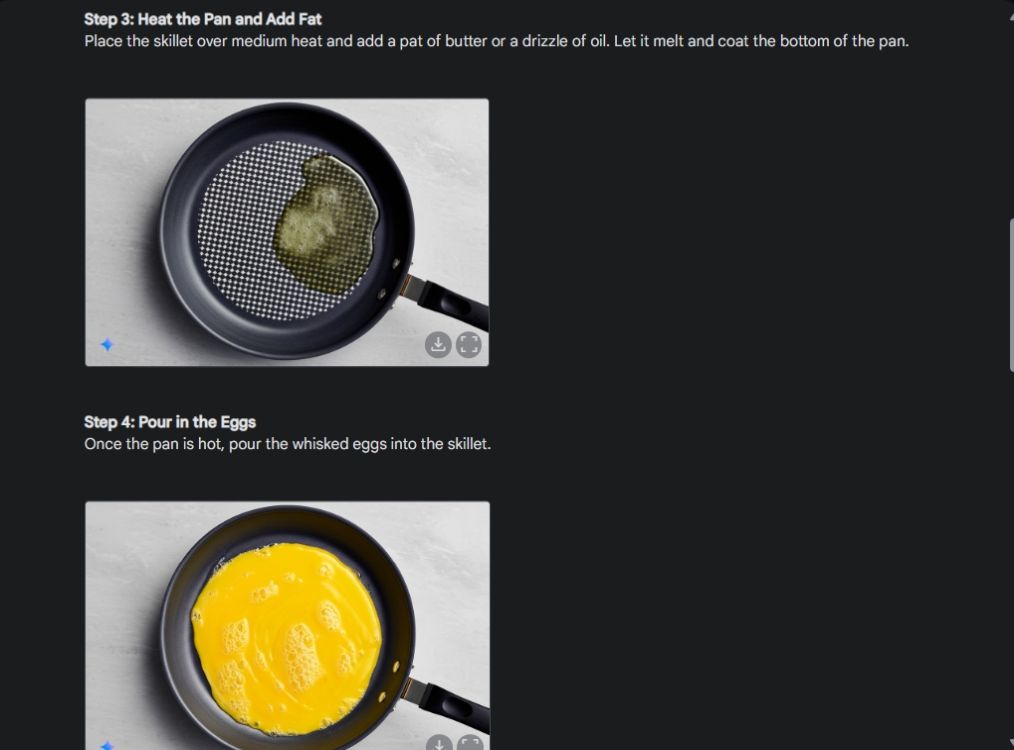

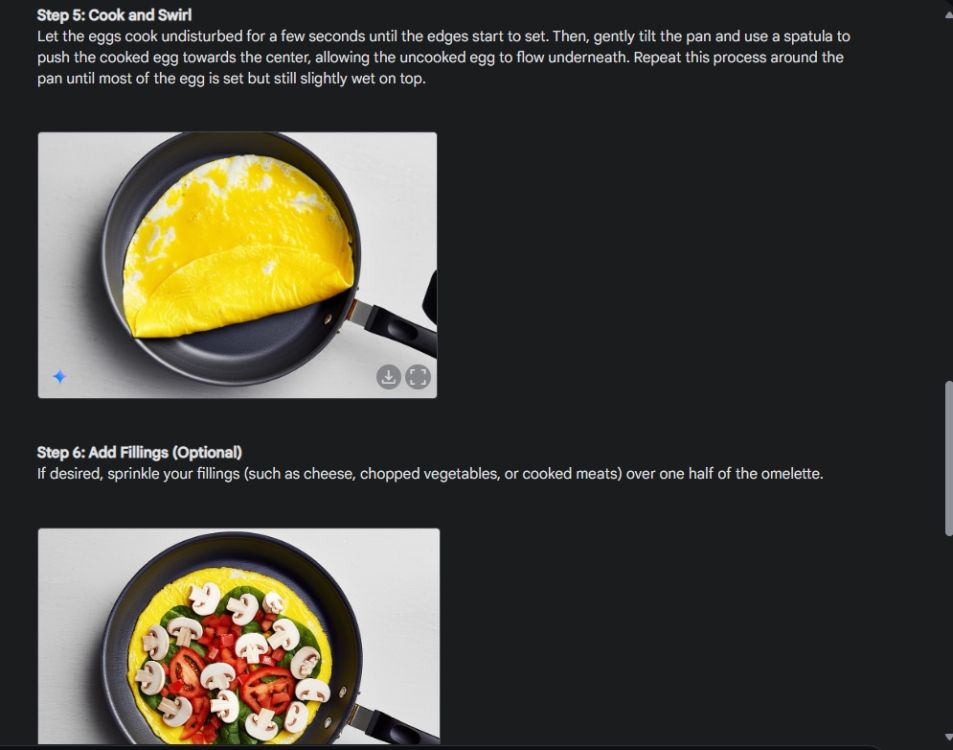
Como você pode ver, os resultados são muito consistentes em todas as imagens, sem erros. Até a tigela é a mesma da segunda foto. Por fim, você pode baixar imagens em resolução 1024 x 680. Dessa forma, você pode criar um guia visual para tudo o que quiser.
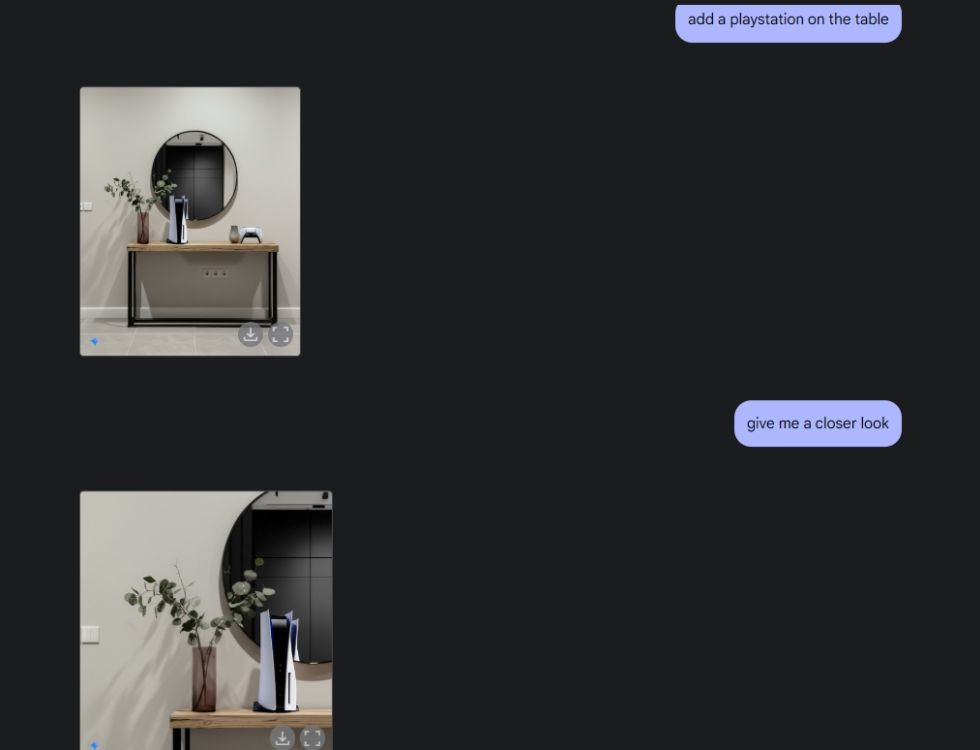
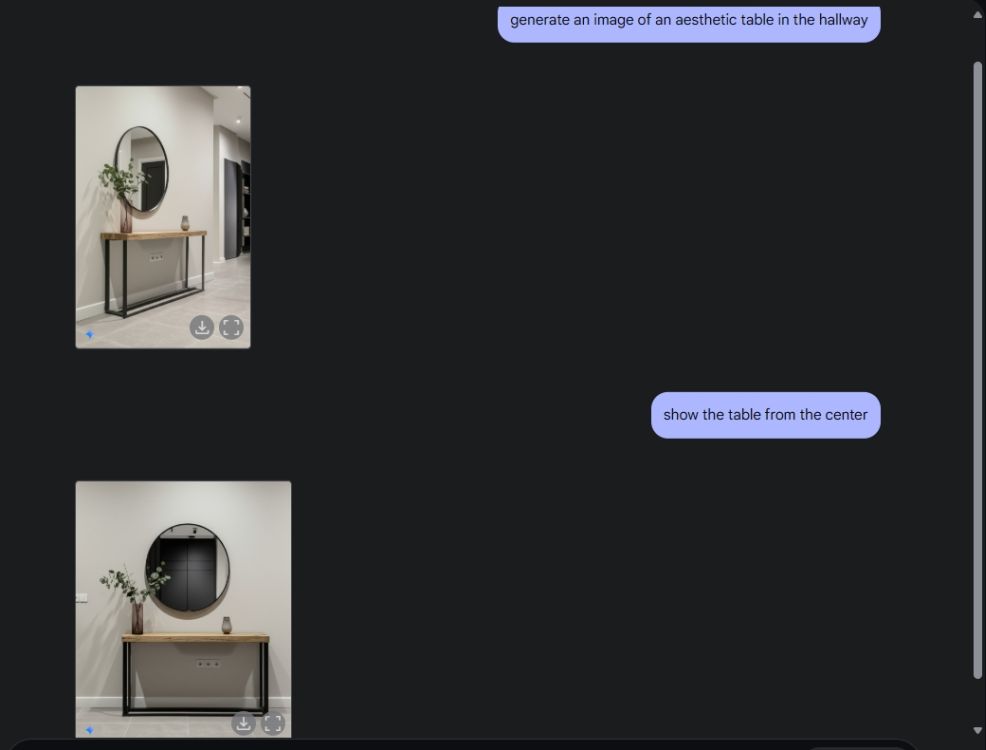
Em seguida, pedi ao Gemini para criar uma imagem estética da mesa e, depois, pedi para ele visualizar a mesa do ângulo central da câmera. Ele fez um trabalho perfeito. Em seguida, pedi para Gemini adicionar um PlayStation à mesa e dar uma olhada mais de perto. Mais uma vez, Gemini acertou em cheio. Como você pode ver abaixo, o modelo de IA também incluiu um reflexo do PS5 no espelho atrás dele.
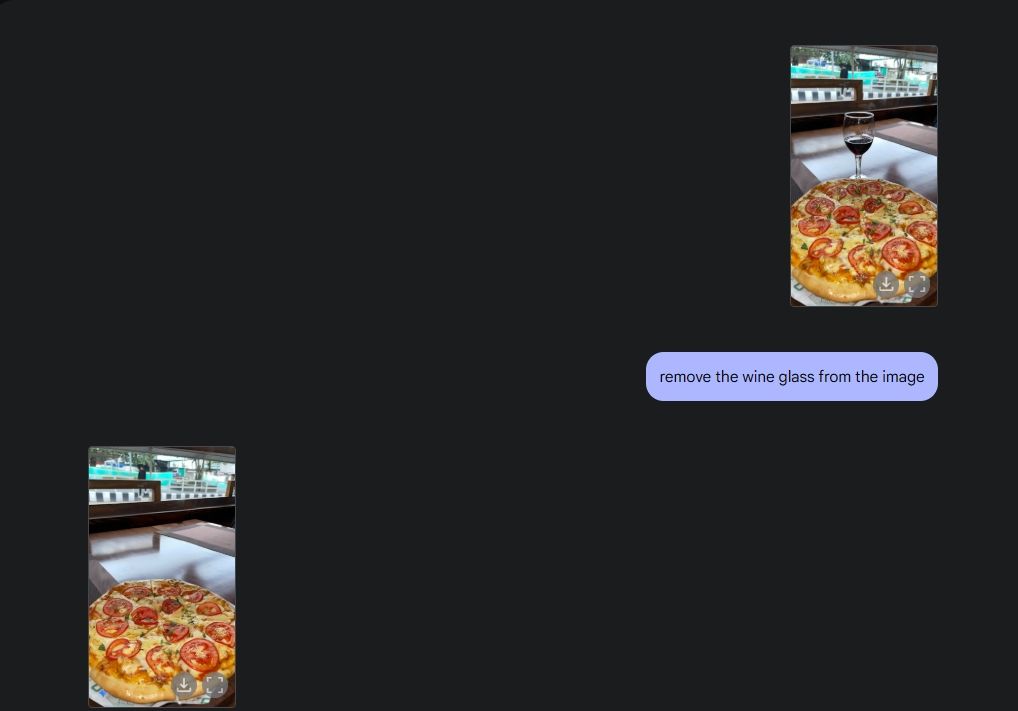
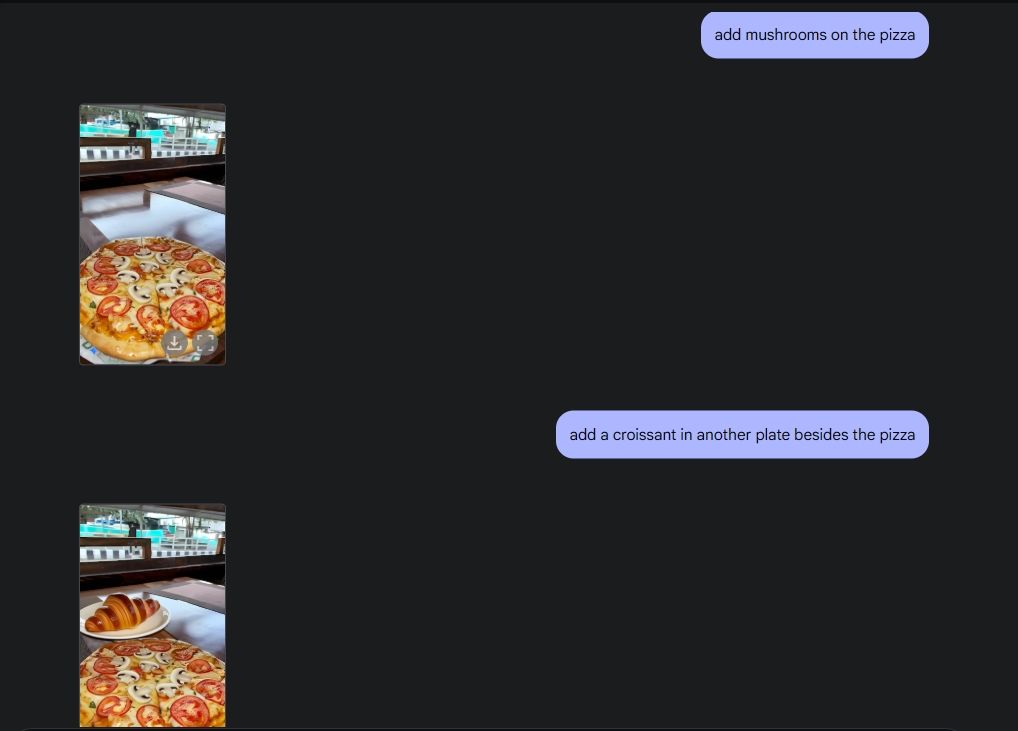
Para demonstrar a edição original da foto, carreguei uma foto da minha galeria e pedi ao Gemini 2.0 para remover a taça de vinho da mesa. Em seguida, pedi para Gemini adicionar cogumelos à pizza, e ele fez um ótimo trabalho. Então pedi para a Gemini adicionar um croissant, e pronto, edição de fotos com IA e todos os seus recursos, graças aos recursos multimídia da Gemini.
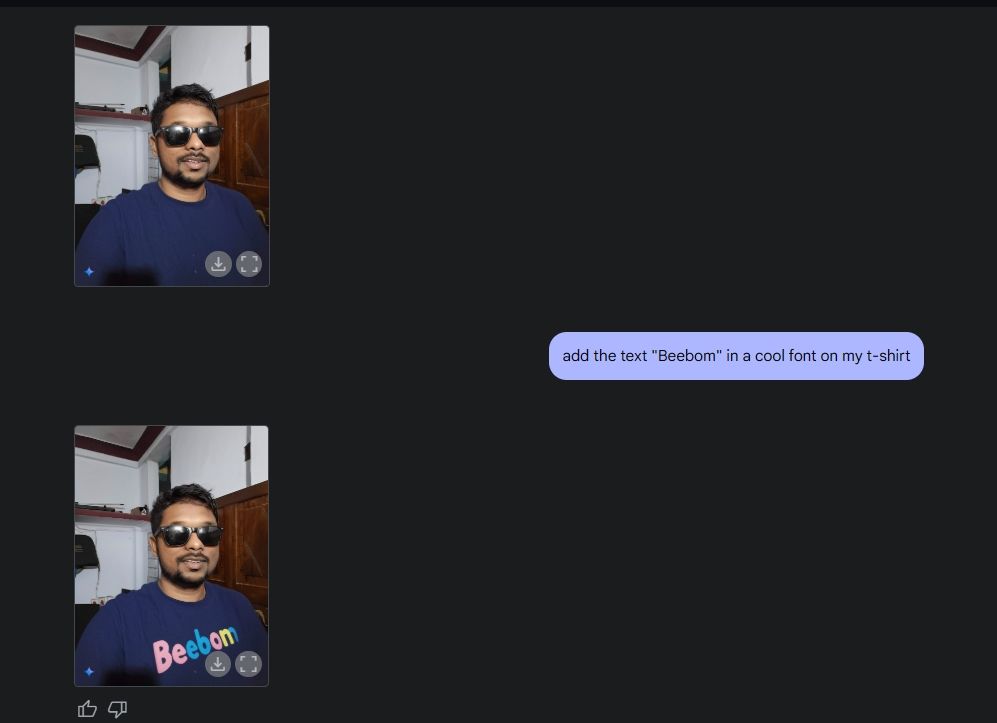
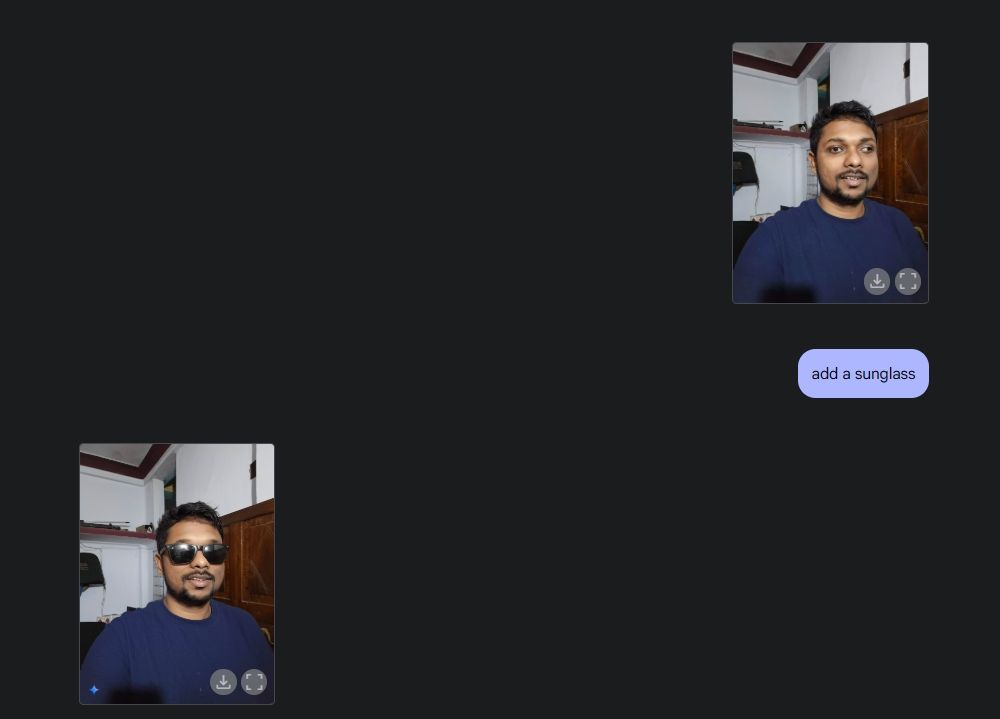
Em seguida, enviei uma foto minha, pedi para a Gemini adicionar óculos de sol e adicionei o texto “Beebom” na minha camiseta. Ambas foram muito bem executadas.
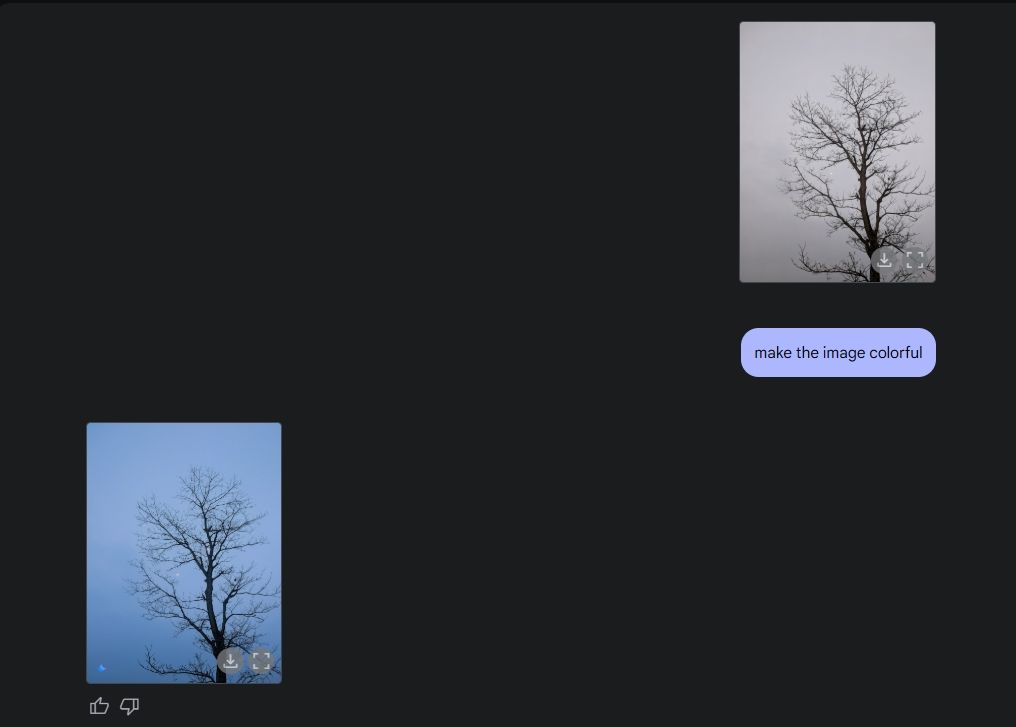
Por fim, pedi para Gêmeos colorir um desenho, e ele se saiu bem nisso também. Quer dizer, a imagem está mais bonita do que antes, sem erros estranhos, distorções ou falta de qualquer parte da imagem.
Há muitos casos de uso que você pode experimentar com os novos recursos multimídia do Gemini. O Google fez um ótimo trabalho com a criação e edição de imagens nativas, e pretendo usá-lo mais detalhadamente nas próximas semanas para testar seus limites.
Após lançar o Veo 2 para criação de vídeos e o Imagen 3 para criação de imagens especializadas, o Google parece ter superado o OpenAI em muitas áreas; Não apenas no campo de geração de texto por IA. Então, será interessante ver o que a OpenAI fará para retomar a liderança com o ChatGPT.
Comentários estão fechados.